[패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 3.1
3주 차 강의.

3주 차에는 Pandas와 Seaborn을 배웠고, 이를 이용하여 다양한 문제들을 풀어보고,
또 직접 데이터를 분석해보는 시간을 가졌다.
잘 이해하고 있는 것인지 모르겠지만, 어찌어찌 수업을 듣다 보니 벌써 반 이상 했다네~!

목차.
- pandas란?
- pandas가 왜 좋은지, 왜 써야하는지
- pandas의 기본 자료구조(Series, DataFrame)
- pandas 라이브러리 불러오기
- 함수들
- pd.Series([ ])
- pd.date_range( )
- pd.DataFrame( )
- DataFrame 기초 method
- head( )
- tail( )
- df.index
- df.coloumns, df.values
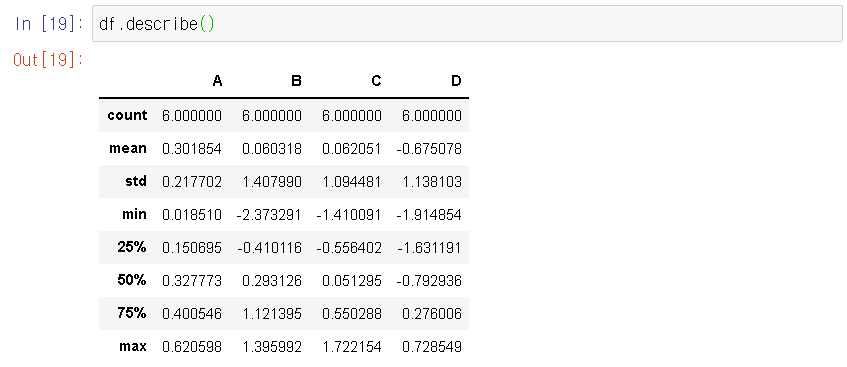
- df.info( )
- df.describe( )
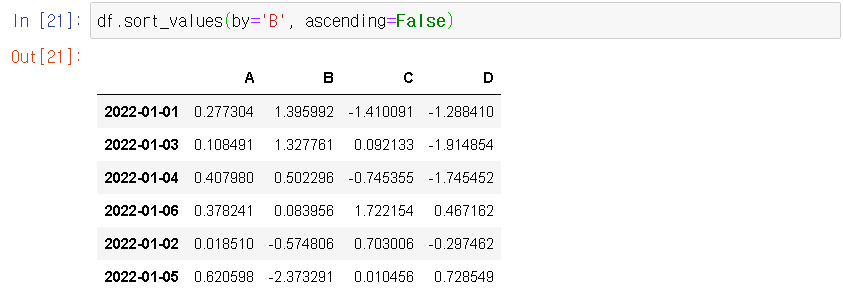
- df.sort_values(by='B', ascending=False)
- DataFrame Indexing
- 'df.loc' slicing
- 'df.iloc' slicing
- fancy indexing
- column 하나 추가하기
- 외부 데이터 읽고 쓰기
- Iris 데이터 셋
- Seaborn이란
- Histplot
- Displot
- Barplot
- Countplot
- Boxplot
- Violinplot
- Lineplot
- Pointplot
- Scatterplot
- Pariplot
- Heatmap
3주 차 후기.
1. pandas란 :
# pandas가 왜 좋은지, 왜 써야 하는지 :
ㅇ "python data analysis"의 약자
ㅇ 정형 데이터 처리에 특화되어 있다
ㅇ 다양한 머신러닝 라이브러리들에 의존성을 가지고 있다 (e.g. scikit-learn, scipy, statsmodel...)
ㅇ python에서 excel의 기능을 사용할 수 있게 됨
BUT : pandas는 numpy array를 베이스로 지원하며 파이썬과 함께 강력한 시너지를 내기 때문에,
= 엑셀 그 이상의 퍼포먼스를 냄!
ㅇ 고성능 데이터 처리에 적합하다.
ㅇ Pandas 라이브러리에서 기본적으로 데이터를 다루는 단위 = DataFrame
(흔히 알고 있는 spreadsheet와 같은 개념)
ㄴ 이러한 형태의 데이터 : 'Structured Data' / 'Panel Data' / 'Tabular Data'라 부름
ㅇ pandas를 공부한다는 것 = 'dataframe의 사용법을 익히고 활용하는 방법을 배운다'는 것
ㅇ pandas를 잘 활용하면 : 대부분의 structured data를 자유자재로 다룰 수 있게 됨
2. pandas의 기본 자료구조(Series, DataFrame) :
# pandas 라이브러리 불러오기
ㅇ pandas → pd

ㅇ DataFrame : 2차원 테이블
ㅇ Series : DataFrame 테이블의 한 줄(행/열)
ㄴ Series의 모임 = DataFrame
# 함수들 :
ㅇ pd.Series([ ]) 함수 (대문자 조심) : 자동으로 세로로 출력해줌

ㅇ pd.date_range( ) 함수 : 날짜 정보를 쉽게 생성해주는 객체도 제공

ㅇ 위 데이터로 6x4 행렬에 -1~1 사이의 랜덤 숫자의 원소를 가지고 테이블 만들기 :
pd.DataFrame( )
index(행) : dates
columns(열) : A~D

3. DataFrame 기초 method :
ㅇ head( ) 함수 : 맨 위 5줄을 보여주는 함수 / 안에 숫자를 넣으면 그만큼 보여줌

ㅇ tail( ) 함수 : 맨 아래에서 5줄

ㅇ df.index 함수 : 어떤 데이터를 받았는데 그 전체 인덱스가 궁금할 때/확인하고 싶을 때

ㅇ df.columns, df.values 함수 :

ㅇ df.info( ) 함수 : index, columns, null/not-null/dtype/memory usage 표시

ㄴ non-null count = 비어있지 않은 셀 개수
ㄴ Dtype은 모두 동일 (homogeneous)
ㅇ df.describe( ) : 기조적인 통계정보를 보여준다!
ㅇ df.sort_values(by='B', ascending=False) : column B를 기준으로 내림차순 정렬

4. DataFrame Indexing :
# Indexing = 데이터에서 어떤 특정 조건을 만족하는 원소를 찾는 방법
전체 DataFrame에서 조건에 만족하는 데이터를 쉽게 찾아서 조작할 때 유용하게 사용할 수 있음
[key - value] → [괄호!]
ㅇ DataFrame에 바로 indexing 하면 : 'column 이름'을 이용하여 찾음
== dictionary의 indexing과 같음 == "key" indexing == "column"(key값)

# 'df.loc' slicing
ㅇ df.loc['날짜'] 함수 : 특정 날짜를 통한 indexing (index를 찾고 싶거나, 이름을 알고 있을 때)
ㅇ df.iloc[ 2 ] 함수 : 특정 위치를 통한 indexing (위에서 3번째 row를 찾고 싶다)

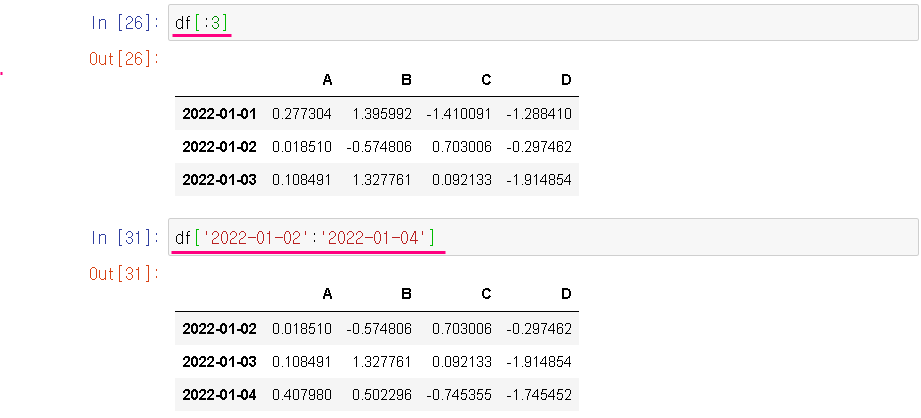
ㅇ DataFrame에서 slicing : 항상 row 단위로 잘림
앞에서 3줄 slicing : df[:3]
index value를 기준으로 slicing : df['2022-01-02':'2022-01-04']
ㅇ df.loc의 2차원 indexing
df.loc[:, ['A', 'B', 'D']] : 모든 row에 대해서 columns는 A, B, D만 가져오라는 의미

ㅇ df.loc['2022-01-03' : '2022-01-05', ['A', 'C']] : slicing을 통해 특정 row 중, columns는 A, C만

ㅇ df.loc['2022-01-02', ['A', 'C']] : 특정 row 한 줄만 slicing (테이블 모양 아님 주의)

ㅇ df.loc['2022-01-03', 'C'] : 특정 row에 특정 column 값

# 'df.iloc' slicing
ㅇ df.iloc[ # ] : 정수를 이용한 indexing과 같다
row 기준 3 = 4번째

ㅇ df.iloc[3:5, 0:2] : row기준 3, 4 + column기준 0, 1 slicing

ㅇ df.iloc[[1,2,4], [0,3]] : slicing이 아닌 직접 리스트 형태로 기재하는 indexing

ㅇ 앞 뒤가 ' : ' 일 때 비교해보기

# pandas는 fancy indexing을 지원함 (사실 numpy에서 지원하기 때문에 pandas도 지원함)
# fancy indexing : 조건문을 통해 indexing을 할 수 있는 방법으로
True와 False를 원소로 하는 리스트를 통해 masking 함
ㅇ df.A > 0 : column A에 있는 원소들 중에 0보다 큰 데이터를 가져오기 :
ㅇ df[df.A > 0] -- DataFrame 입력
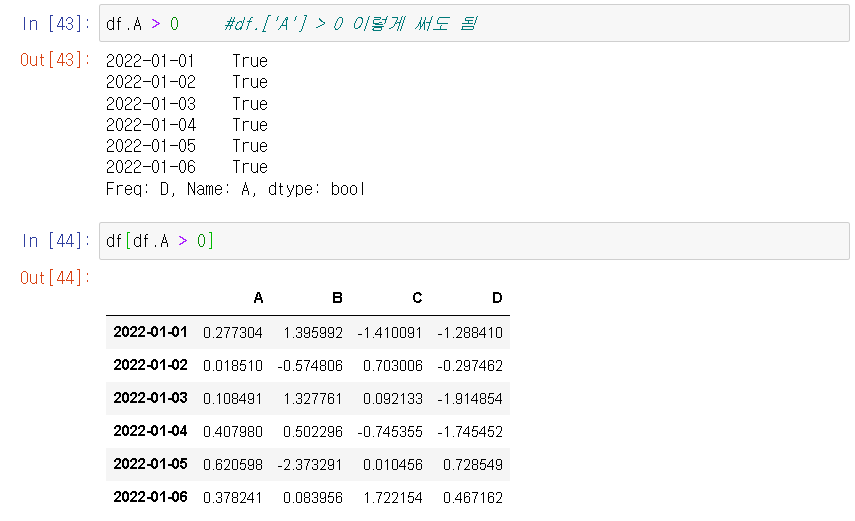

ㄴ NaN = 조건에 맞지 않을 때 나옴
ㅇ chain indexing : indexing의 앞에서부터 뒤로 쭉 순서대로 적용

# column 하나 추가하기 :

ㅇ df.isin 함수 : 해당 value들이 들어있는 row에 대해 True를 가지는 Series를 리턴함

5. 외부 데이터 읽고 쓰기 :
# Iris 데이터 셋 = 머신러닝/통계학에서 유명함
ㄴ 붓꽃
ㄴ 3 가지 종류를 구분해서 사용 가능한 데이터 셋
→ pandas의 기능을 사용하여, 실제로 학습이 가능한 형태로 데이터를 정제하는 연습
1. Iris.csv 파일 불러오기 :

2. data.info( ) 함수를 통해서 Dtype 확인 :
ㄴ [복습] column별로 동일한 Dtype이어야 하는데
해당 column에 하나라도 string이 있으면 Dtype = object로 표시함


3. 위 Species column(Dtype = object)을 뽑아서 숫자로 바꾸기 :
ㄴ 이 column이 어떻게 구성되어있는지 확인하기 위함.
data["Species"]를 치면 수많은 데이터일 때는 '...'으로 표기가 되어 다 안 나옴.
→ set(data["Species"]) 함수 사용

> 숫자로 바꿀 계획 :
Iris-setosa → 0
Iris-versicolor → 1
Iris-virginica → 2


4. 데이터 지정 이름.to_csv(" ") : 새로 저장하기

1. kaggle_survey_2020_responses.csv 파일 불러오기 : (방법 똑같음)

2. 박사학위 소지자들만 고르기 :
data2[data2["Q4"] == "Doctoral degree"]
ㄴ data2 테이블 안에 > Q4열에서 > "Doctoral degree"만 출력해줘

3. 박사학위면서 + 대한민국 국적을 가진 사람들 고르기 :
data2[(data2["Q4"] == "Doctoral degree") & (data2["Q3"].isin(["Republic of Korea", "South Korea"]))]

6. Seaborn이란 :
= statistical data visualization
ㄴ matplotlib을 기본으로 다양한 시각화 기법을 제공하는 라이브러리
ㄴ 시각화 라이브러리 중에서 powerful 함 = 예쁨, 쉽게 정보를 잘 확인할 수 있음
ㄴ pandas DataFrame과 호환이 매우 잘 됨
e.g. sns.xxxplot(data=df) ← 기본 세팅!
ㄴ plot 만들 때 x, y 꼭 다 쓸 필요는 없고, 비워두면 자동으로 채워줌
Seaborn 공식 홈페이지 : https://seaborn.pydata.org/
seaborn: statistical data visualization — seaborn 0.11.2 documentation
Seaborn is a Python data visualization library based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics. For a brief introduction to the ideas behind the library, you can read the introductory note
seaborn.pydata.org
ㄴ 'Gallery' 페이지 애용하기!
# 라이브러리 & 데이터를 불러오고, 시각화를 위한 세팅 :

# Histplot :
= 가장 기본적으로 사용되는 히스토그램을 출력하는 plot.
= 전체 데이터를 특정 구간별 정보를 확인할 때 사용
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")

sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple='stack')

# Displot :
= distribution들을 여러 subplot들로 나눠서 출력해줌
= displot에 kind를 변경하는 것으로, histplot, kdeplot, ecdfplot 모두 출력 가능
e.g. displot(kind="hist")
sns.displot(data=penguins, x='flipper_length_mm', hue='species')

sns.displot(data=penguins, x='flipper_length_mm', hue='species', col='species')

# Barplot :
= 어떤 데이터에 대한 값의 크기를 막대로 보여줌 (a.k.a. 막대그래프)
= 가로 / 세로 두 가지로 모두 출력 가능
= 히스토그램과는 다름!
sns.barplot(data=penguins, x='flipper_length_mm', y='species', hue='species')

sns.barplot(data=penguins, y='flipper_length_mm', x='species', hue='species')

# Countplot :
= 범주형 속성을 가지는 데이터들의 histogram을 보여줌
= 종류별 count를 보여주는 방법
sns.countplot(data=penguins, x='species')

sns.countplot(data=penguins, x='species', hue='sex')

# Boxplot :
= 데이터의 각 종류별로 사분위 수(quantile)를 표시함
= 데이터의 전체적인 분포를 확인하기 좋은 시각화 기법
= box와 전체 range의 그림을 통해 outlier를 찾기 쉬움(IQR : Inter-Quantile Range)
sns.boxplot(data=penguins, x='flipper_length_mm', y='species', hue='species')

ㄴ 박스 가운데 선 = average
ㄴ 전체 중 50%가 박스로 색칠됨
ㄴ ◆ = outlier(s)
ㄴ 중심에 얼마나 모여있느냐를 보기 쉬움
sns.boxplot(data=penguins, x='flipper_length_mm', y='species', hue='sex')

# Violinplot :
= 데이터에 대한 분포 자체를 보여줌
= boxplot과 비슷하지만, 전체 분포에 대한 그림을 보여준다는 점에서 boxplot과 다름
= 보통 boxplot과 함께 표시하면 :
- 평균 근처에 데이터가 얼마나 있는지(boxplot)
- 전체적으로 어떻게 퍼져있는지(violinplot) 모두 확인이 가능

# Lineplot :
= 특정 데이터를 x, y로 표시하여 관계를 확인할 수 있음(선 그래프)
= 수치형 지표들 간의 경향을 파악할 때 많이 사용합니다.
sns.lineplot(data=penguins, x='body_mass_g', y='flipper_length_mm', hue='species')

# Pointplot :
= 특정 수치 데이터를 error bar와 함께 출력해줌
= 수치 데이터를 다양한 각도에서 한 번에 바라보고 싶을 때 사용합니다.
= 데이터와 error bar를 한 번에 찍어주기 때문에, 살펴보고 싶은 특정 지표들만 사용하는 것이 좋음
sns.pointplot(data=penguins, y='flipper_length_mm', x='sex', hue='species')

# Scatterplot :
= lineplot과 비슷하게 x, y에 대한 전체적인 분포를 확인함 (산포도)
= lineplot은 경향성에 초점을 둔다면,
scatterplot은 데이터 그 자체가 퍼져있는 모양에 중점을 둠
sns.scatterplot(data=penguins, x='bill_length_mm', y='bill_depth_mm', hue='sex')

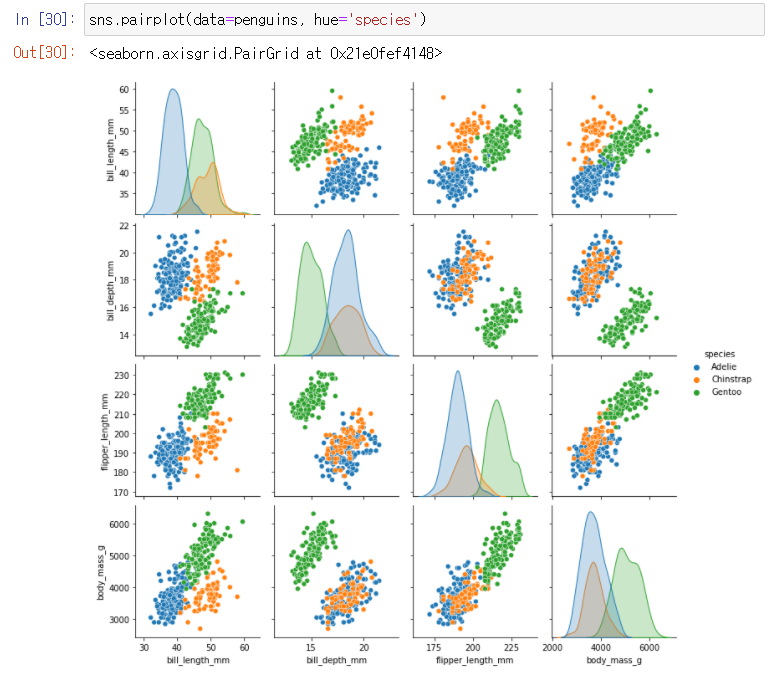
# Pairplot :
= 주어진 데이터의 각 feature들 사이의 관계를 표시
= scatterplot, FacetGrid, kdeplot을 이용하여 feature 간의 관계를 잘 보여줌
각 feature에 대해 계산된 모든 결과를 보여주기 때문에, feature가 많은 경우 사용하기 적합하지 않음
sns.pairplot(data=penguins, hue='species') → hue만 지정하면 됨
# Heatmap :
= 정사각형 그림에 데이터에 대한 정도 차이를 색 차이로 보여줌
= 열화상 카메라로 사물을 찍은 것처럼 정보의 차이를 보여줌
= pairplot과 비슷하게 feature 간 관계를 시각화할 때 많이 사용
ㅇ 각 feature간 상관관계를 파악하기 위해 Correlation matrix를 만듦
데이터 이름.corr( )

ㅇ 글자로 된 애들을 먼저(아까 한 것처럼) 0, 1, 2로 바꿔주고 작업하면 되긴 하지만
일단 그냥 위에 4개의 데이터로 진행 :

ㅇ 그래프 오른쪽 : 컬러바 = 정보차이를 알려줌
검정으로 갈수록 음의 상관관계(-1에 가까워진다는 뜻), vice versa
3주 차 후기.
Iris는 오래된 내 영어 이름인데(거의 내 분신) 이렇게 파이썬 공부하다가 만나니까
느낌이 색다르고 괜한 친근감이 느껴진다ㅎㅎ🌸
이번 주는 pandas와 Seaborn을 메인으로 배워봤고, 또 직접 시중에 있는 데이터를 가져와서
분석을 해볼 수 있는 기회가 주어져서 신기하고 재밌었다.
(느슨했던 마인드가 다시 잡힌 느낌!)
내가 이 패캠 수강하기 전에 목표가 '데이터 분석에 자신감이 생기는 것'이었는데
조만간 이 목표를 달성했으면 좋겠다 :)
파이팅! ⭐
print("to be continued...")