[패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 5
5주 차 강의.

정말 정말 마지막 주다~
미니 프로젝트 : 쇼핑몰 주문 데이터를 활용해서 데이터 분석을 해보았다!

목차.
- 가상 쇼핑몰 고객 주문 데이터
- 매출, 가장 많이 팔린 아이템 확인하기
- 매출 데이터로부터 insight
- 우수고객 선별하기 + 고객 코호트 분석
- 로그데이터 파악하여 고객 이탈 페이지 확인하기
1. 가상 쇼핑몰 고객 주문 데이터
ㅇ 중점을 두고 보는 부분 :
1. 현상태 파악 분석
-- 단순하게 '지난주 매출 대비 이번 주 매출이 많이 줄었다' X
-- '지난주 매출은 #고, 이번 주 매출은 #고, 고객 증가량이 #다.' 등 정확한 값이 필요하다
2. 의사결정에 도움이 될만한 요소를 뽑는 분석
-- 예전에는 감으로 이루어졌다면, 이제는 데이터의 팩트로 결정을 함.
데이터 출처 : 영국 기반 온라인 retail 사이트의 2010/12 - 2011/12간의 주문 기록 데이터 (약 50만 건의 데이터)
https://archive.ics.uci.edu/ml/datasets/Online+Retail
UCI Machine Learning Repository: Online Retail Data Set
Online Retail Data Set Download: Data Folder, Data Set Description Abstract: This is a transnational data set which contains all the transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based and registered non-store online retail. Data Set Ch
archive.ics.uci.edu
ㅇ 시작은 numpy, pandas 불러오기 :

ㅇ 리테일 칼럼 확인하기 :

• invoiceNo: 주문 번호
• StockCode: 아이템 아이디
• Description: 상품 설명
• Quantity: 상품 주문 수량
• InvoiceDate: 주문 시각
• UnitPrice: 상품 가격(동일한 통화)
• CustomerID: 고객 아이디
• Country: 고객 거주 지역(국가)
ㅇ 데이터 살펴보기 :



ㅇ Data Cleansing :
# null 처리 :

ㄴ null CustomerID(135080개) 제거 :

# 비즈니스 로직에 맞지 않는 데이터 처리 (음수 아이템 삭제) :


ㅇ 데이터 타입 변경 :
# int32로 데이터 타입 변경 = CustomerID가 39만 개 밖에 없기 때문에 32비트로 충분히 가능

ㅇ 새로운 column 추가 :

ㅇ 데이터 새로 저장 :

# 이제 데이터 정리 완료, 분석 시작
2. 매출, 가장 많이 팔린 아이템 확인하기

ㅇ 데이터는 마지막에 저장한 정제된 데이터 사용 (OnlineRetailClean.csv) :

ㅇ 날짜 타입 데이터 변환 : 문자열로 로딩하는 것보다 date/datetime 타입으로 로딩하는 것이 분석에 용이함
# pd.to_datetime( ) 함수

ㅇ 해당 기간 동안의 매출 : 매출 분석
# 전체 매출 :

# 국가별 매출 :

ㄴ 막대그래프로 확인해보기 :



ㄴ 분석 결과 : 사실상 거의 영국에만 사업을 집중하고 있다고 볼 수 있음
ㄴ 그래프 형식을 계속 같이 사용할 것이기 때문에 함수화 시켜버리기 : plot_bar


# 월별 매출 :


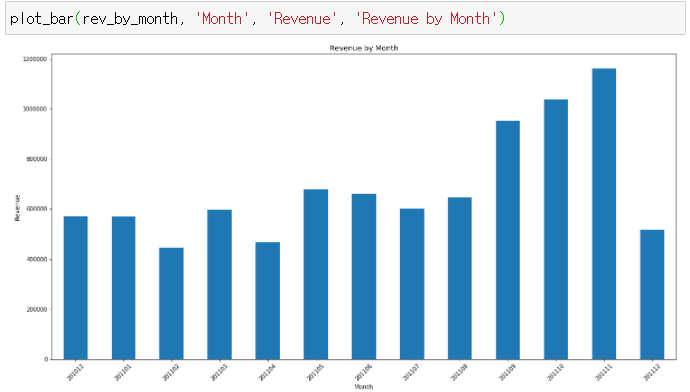
ㄴ 12월은 ↓↓ 12월 9일이 가장 최신 데이터이기 때문에 사실상 그래프에 데이터가 모두 보이지 않음

# 요일별 매출 :

ㄴ 이유는 모르지만, 5(토요일)가 비어있음 -- 회사 내부 사정일 수도?


# 시간별 매출 :
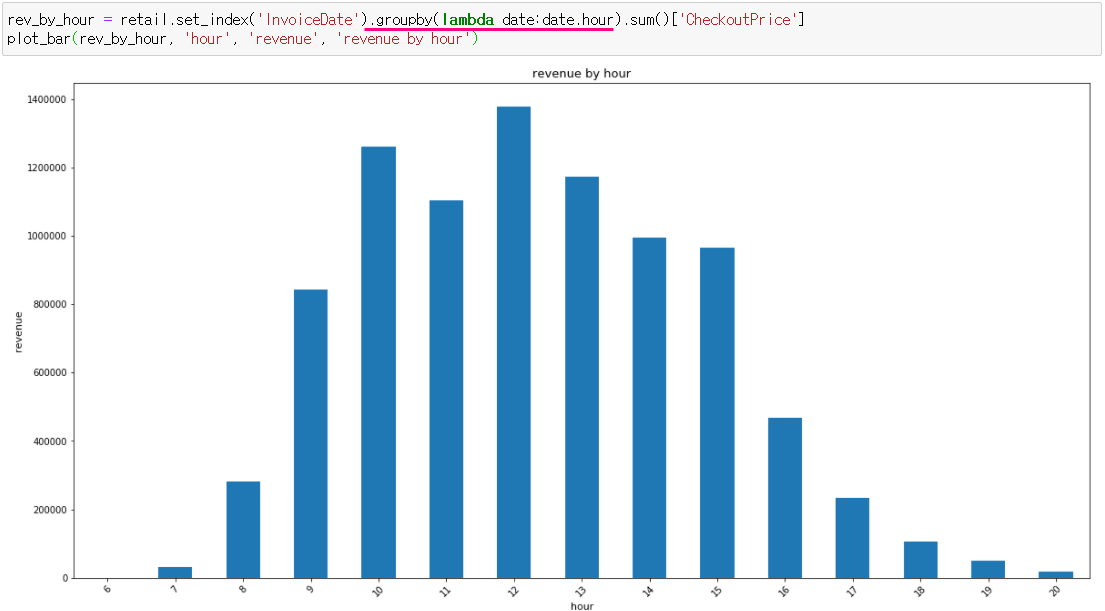
ㄴ 12시까지 점차 주문 수가 늘어나다가, 15시 이후 급락함
왤까? 퇴근일 수도?
→ 이 시간 때는 버리고 많이 주문하는 시간 때에 집중하자
3. 매출 데이터로부터 insight :
- 전체 매출의 82%가 UK에서 발생
- 11년도의 가장 많은 주문이 발생한 달 : 11월 (12월의 전체 데이터가 반영이 되지 않았음)
# 11, 12월의 판매량이 압도(블랙프라이데이, 사이버 먼데이, 크리스마스 휴일)
- 일주일 중 목요일까지는 성장세를 보이다가, 이후로 하락(토요일에는 주문 X)
- 7시를 시작으로 주문이 시작되어 12시까지 증가세, 15시까지 하락을, 15시 이후부터 급락
ㅇ 제품별 metrics :
- Top 10 판매 제품
- Top 10 매출 제품


ㅇ top 3 아이템의 월별 판매량 추이 : 가장 많이 팔린 3 개의 아이템
monthly_top3 = retail.set_index('InvoiceDate').groupby(['StockCode', extract_month]).sum()[['Quantity', 'CheckoutPrice']].loc[top_selling.index]

4. 우수고객 선별하기 + 고객 코호트 분석
# Cohort = 특정 기간 동안 같은 경험을 한 집단 (e.g. 고객의 retension(재구매) 분석)
ㅇ 우수 고객 확인 :
- 구매 횟수 기준 :

- 지불 금액 기준 :

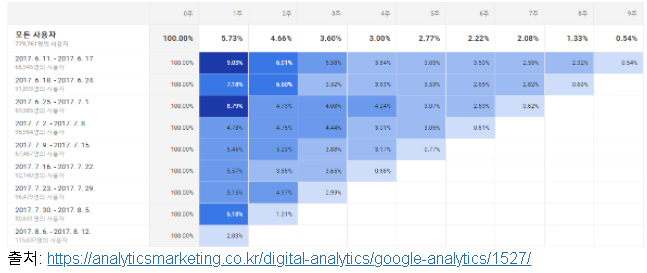
ㅇ 사용자 retension 분석 :
- 월간 사용자 cohort를 바탕으로 월별 재구매율(retention) 분석
- heatmap으로 한눈에 재구매율을 파악 가능 ↓↓
ㅇ 사용자 기준으로 최초 구매한 월(month) 연산하기 :
- 구매 월만! (일, 시분초 제거) :

- transform( )

- 최초 구매월 & 재구매한 월의 차이 구하기 :

- 최초 구매 월, MonthPassed를 기준으로 고객 수 카운팅 : cohort

- pivot table 작성 :
# pivot 함수를 이용하여
ㄴ index는 MonthStarted,
ㄴ columns는 MonthPassed로 변경하기
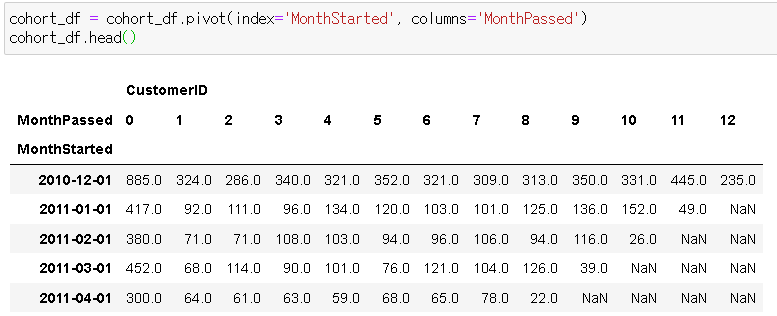
# cohort 및 decimal point 줄이고, 비율 찾기

- heatmap으로 출력 (seaborn) :

ㅇ 데이터 기반으로 의사 결정하기 -- push notif. 언제 보내야 할까? :

- 쿠폰 발송을 할 때, push를 언제 보내는 게 좋을까?
# 고객에게 쿠폰 발송을 한다고 기획하고, 회의를 한다고 가정 :
A: 쿠폰을 언제 보내는 게 좋을까요?
B: 아침에 출퇴근 시간에 보내는 게 좋을까요?
C: 점심 먹고 졸린데 그때 보내보죠?
D: 자기 전에 스마트폰 많이 하던데 그때는 어떨까요?
A: 그러면 평균 시간을 내볼까요?
K: 아 데이터를 확인해보는 게 맞지 않을까요? 언제 고객이 주로 주문을 하는지?
# 회의를 하다 보면 의사결정이 본인/주변의 경험에 의해서 이뤄지는 것을 많이 볼 수 있음
# 현상태에서는 가장 많이 주문이 일어나는 시점에서 하는 것이 가장 직관적인 판단
# 순서 :
(1) 데이터로 파악
(2) 가설 제시
(3) 가설 검증
(4) 1-3 반복
# 시간(hour, minute)과 주로 관련되기 때문에 역시 InvoiceDate가 중요


# 고객을 3 그룹으로 나눠서 효율 실험 가능 :
1. 12시 #명
2. 13시 #명
3. 14시 #명
# 시간대를 더 잘게 쪼개는 방법 : 30분 단위로 쪼개기

# 시간이 들어왔을 때
15분이라면 = 00분
45분이라면 = 30분


# 시간대별 비율 확인해보기 :

ㅇ 사용자별 각 시간별 주문 량 계산하기 :

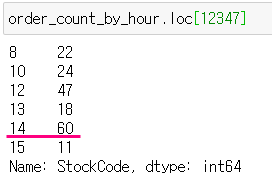
ㅇ 사용자별 최대 주문 시간 계산하기 :

ㅇ 해당 시간 indexing :


5. 로그데이터 파악하여 고객 이탈 페이지 확인하기
고객의 이탈 : 보통 = 물품 서칭 > 상품의 상세페이지 > 장바구니/바로 결제하는 고객이 있겠지만,
결제까지 가지 못하고 중간 어딘가에서 이탈해버리는 경우를 파악하는 것. (언제 나가는지)
# 고객 이탈 페이지를 확인하는 것 = funnel analysis
ㄴ with 로그데이터
ㄴ 웹서버의 로그데이터 :
ㅇ 웹서버에 클라이언트로의 요청(request) 전달 시,
해당 요청에 대한 정보(ip, 시각, 방문 페이지 등등)를 기록하는 파일
ㅇ 기록되는 로그의 포맷(format)의 표준이 있으나 설정으로 포맷 변경 가능
ㅇ 로그 데이터는 주로 웹 서버의 디버깅, 데이터 분석 등의 형태로 사용됨
ㄴ session = 사용자가 active 하게 그 사이트를 이용하는 기간
# 예제에서 사용하는 형식 :
ip 세션아이디 사용자 식별자 시각 요청 페이지 상태 코드 바이트 사이즈
1.0.0.1 sessionid user59 [16/Dec/2019:02:00:08] GET /checkout 200 1508

ㄴ 얼마나 많은 사람들이 결제까지 가는지 + 얼마나 많은 사람들이 이탈을 하는지

ㅇ 날짜 형식 변환하기 :


ㅇ 어떤 페이지에서 고객이 이탈을 할까? :
- 고객 이탈 페이지를 알면 해당 페이지를 분석하여 고객을 최종 단계로 더 많이 유도 가능
- 대부분의 경우 다음 스텝으로 넘어갈 때의 장벽이(신용카드 입력, 정보 입력 등등) 높은 경우가 해당됨
(장벽을 낮춰주기)

ㅇ funnel step -- DataFrame 생성 :

ㅇ session & url로 grouping :
- user_id가 아닌 session으로 하는 이유 :
ㄴ 동일한 유저가 다른 세션으로 접속한 경우도, 다른 경우로 간주해야 하기 때문
(유저가 매일 항상 같은 움직임이 아님)
- session_id와 url로 그루핑 하여 가장 시간대가 빠른 해당 이벤트에 대해 추출
ㄴ 고객이 단순하게 결제까지 가지 않고, 다시 돌아가서 다른 제품을 보고 또 보고 할 수도 있기 때문


ㅇ funnel table 생성 :
- 각 funnel의 step이 순서대로 columns으로 오도록 변경

# 근데 1, 2, 3, 4로 열이 적혀있어서 어디까지 갔는지 모르기 때문에 이름으로 변경해주기 :

ㅇ funnel count 계산 : 각 funnel step별 카운트 계산

# step 1 : 419명
# step 2 : 419명 중 351명이 다음 step으로 넘어감
# step 3 : 261명
# step 4 : 84명이 결제까지 완료함


ㅇ 평균 시간 계산 : 각 funnel 별 소요 시간 계산



즉, 카트에서 결제까지 평균 30분 이상 걸렸기 때문에 = 오래 걸렸기 때문에 결제 창에 문제가 있을 수도 있겠다는 결론을 내릴 수 있다.
5주 차 후기.
어쩌다 강의를 모두 들었고, 부분적으로 모르는 부분들과 이해 안 되는 부분들이 있지만,
구글에 생각보다 설명을 잘해놔서 다행이라고 생각이 들었다.
파이널 과제 때문에 조금은 재촉이 되었던 5주였지만
어려워서 하기 싫어! 가 아니라 흥미를 느끼게 해 준 강의들이어서 다행이었다.
조금은 컴퓨터와 더 친해진 것 같고, 얼른 내 실력을 조금 더 키워서 (취업부터 해야겠지만) 실무에서도 사용해보고 싶다.
스터디 임원들과 게더타운에서 말고 실제로 만나서 파이널 프로젝트를 서로 도와가면서 해보기로 했다.
새로운 사람들을 만나서 비슷한 분야에 관심을 갖고 함께 공부를 할 수 있게 되어서 감사하다.
(+아이 라이크 뉴페이스~)
파이널 과제를 잘할 수 있을지는 모르겠지만,
정말 이젠 끝이 보인다!
파이팅! ⭐⭐