4주 차 강의.

이제 파이썬의 기초적인 지식과 사용법을 끝내고 4주 차부터는 실전 데이터 분석 연습에 돌입했다!
이번 주는 이전에 배운 것들을 토대로 현업에 어떻게 적용이 가능한지, 분석은 어떻게 하는지를 알아보았다.
정말 이제는 끝이 보이는데, 실전 연습을 해보면서 또 다른 흥미를 느낄 생각에 설렌다 ㅎㅎ

목차.
- 데이터 처리 How-To
- 마케팅 데이터 분석을 위한 Domain Knowledge
- matplotlib
- 검색광고 데이터 분석
- 데이터 전처리
- Pandas를 활용한 데이터 탐색 실습
- 시각화
- 데이터 분석
- 광고그룹 분석
- 광고그룹 기준 데이터 전처리
- 데이터 시각화
1. 데이터 처리 How-To
ㅇ 마케팅 현업에서 각광받고 있는 파이썬 :
- 대량 데이터 분석 능력 요구!
- 광고주가 요구하는 데이터 분석 수준 증대!
- 배우기 쉽고, 데이터 분석에 효율적인 파이썬에 대한 니즈 증대!
ㅇ 4주 차에서는 2 가지 라이브러리 주요 사용 :
(1) 데이터 분석 및 처리를 위한 파이썬 라이브러리 - pandas
(2) 시각화를 위한 파이썬 라이브러리 - matplotlib
ㅇ 사용할 두 가지 매체 :
(1) 광고매체 데이터 → 출처: 네이버, 페이스북, 구글 ...
(2) 고객 데이터(마케팅 활동으로 쌓이는 고객들의 정보)
→ 출처: UCI machine learning epository
1-1. 마케팅 데이터 분석을 위한 Domain Knowledge :
ㅇ 광고의 진행 과정 :
광고 매체(네이버, 구글 등)에 돈을 주면 → 노출을 시켜준다 → 사람들이 광고를 클릭(접속) → 구매
ㅇ 광고 성과지표 :

# CTR = 높을수록 👍🏻
# CPM = 낮을수록 광고비를 효과적으로 잘 사용했다고 판단
# CPC = 낮을수록 👍🏻
# CPA = 낮을수록 👍🏻
# imp = impression(노출, 노출 수)
# clk = click(클릭)
# conv = conversion(구매)
# cost = 광고비

1-2. matplotlib :
ㅇ 특징 : import matplotlib.pyplot as plt
- 시각화 라이브러리 matplotlib
- matplotlib은 pandas의 데이터 프레임, 시리즈 자료구조와 함께 사용 가능
- 따라서 데이터 처리와 시각화를 함께 진행할 수 있음
- 아나콘다(anaconda)를 설치했다면 별도의 설치 과정이 필요 없음
ㅇ 머신러닝의 과정 (5 가지 단계) :
1. 데이터 수집
2. 데이터 전처리
3. 데이터 탐색 ◆시각화 과정◆
4. 모델 선택
5. 모델 평가 및 적용
ㅇ 그래프 DataFrame 시각화 :

1. 선 그래프
df.plot()
plt.show()
2. 바(막대) 그래프
df.plot.bar()
plt.show()
3. 가로 막대그래프
df.plot.barh()
plt.show()
4. 히스토그램
df.plot.hist()
plt.show()
4-1. 히스토그램 구간 설정
df.plot.hist(bins=range(1,9,1)) → 1~8까지 구간 설정
plt.show()
ㅇ 그래프 옵션 추가하기 :
1. 막대그래프 크기 설정
df.plot.bar(figsize=[5,5]) → figsize라는 리스트 추가
plt.show()
2. 그래프 제목 설정
df.plot.bar(figsize=[5,5])
plt.title('Sample Graph')
plt.show()
2-1. 그래프 제목 크기 설정
df.plot.bar(figsize=[5,5])
plt.title('Sample Graph', fontsize=18)
plt.show()
3. 그래프 x축 제목 설정
df.plot.bar(figsize=[5,5])
plt.title('Sample Graph', fontsize=18)
plt.xlabel('xlabel')
plt.show()
3-1. 그래프 x축 제목 크기 설정
df.plot.bar(figsize=[5,5])
plt.title('Sample Graph', fontsize=18)
plt.xlabel('xlabel', fontsize=15)
plt.show()
# y축은 plt.ylabel로 똑같이 하면 됨
4. 그래프 x, y축 눈금 설정 (위치, 이름, 폰트 사이즈, 각도)


ㅇ 그래프 series 시각화 :
ㄴ series = DataFrame의 하나하나의 열

그래프 만들기 위와 같음
df['철수'].plot.bar()
plt.show()
2. 검색광고 데이터 분석
ㅇ 분석 목표 :
1. 중점관리 키워드, 저효율 키워드 추출
2. 중점관리 광고그룹, 저효율 광고그룹 추출
ㅇ 분석 과정 :
1. 데이터 전처리
2. 데이터 탐색
3. 시각화
4. 데이터 분석

2-1 데이터 전처리 :
ㅇ 먼저 pandas 라이브러리를 불러온다 :

ㅇ read_excel 함수를 사용하여 파이썬에 데이터 불러오기 :
- 파이썬의 디렉터리 경로 구분자 : 슬래시(/)
- 운영체제별 디렉터리 경로 구분자 :
ㄴ Mac의 경우 : 슬래시(/)
ㄴ 윈도의 경우 : 역슬래시(\ or \)
# Windows는 \\ or / or r을 경로 맨 앞에 넣어준다

ㅇ skiprows 함수를 사용하여 불필요한 행 제거하기 :
# 첫 행 삭제하기 :

# 여러 행 삭제하기 :

ㅇ 결측치 확인하기 :
# 열 단위로 확인하기

# 행 단위로 확인하기

ㅇ DataFrame의 열 단위 수치 연산 및 데이터 타입 다루기 :
- 클릭수
= 한 번의 클릭이 총 몇 번 이루어졌는지 나타내는 지표
→ 반올림 처리, 일의 자릿수로 변경하기
# round('열 이름', 0) 함수 적용 : 첫 번째 자리까지 반올림

# round 연습!!!

# 클릭 변수 확인 하기 :

# 소수점 제거 = 실수(float) → 정수(int)로 변경 하기 :

- 클릭률(CTR) = 클릭수 / 노출수 * 100
# 열 단위로 확인 가능 :

# 바로 기존 테이블에 나타낼 수도 있다 :

# 열과 열에 대한 수치 연산도 가능!

- 평균클릭비용(VAT 포함, 원) : 칼럼명에 원 단위로 명시됨
→ 반올림 처리, 일의 자릿수로 변경하기

2-2 Pandas를 활용한 데이터 탐색 실습 :
- 데이터 탐색과정에서 사용되는 함수 살펴보기 + 실전 사례를 통해 사용법을 익히기
ㅇ .head( ) = 기본 5행 // .head(#) = 첫 #행
ㅇ .tail( ) = 끝 #행
ㅇ .shape = dataframe의 크기(행, 열의 수)
ㅇ .describe( ) = 각 열에 대한 기술 통계량
= 데이터의 수, 평균, 표준편차, 최솟값, 1 사분위수, 2 사분위수, 3 사분위수, 최댓값
→ 자수 표기 법 : exoponential notation; 10^n
ㅇ pd.set_option('display.float_format', '{:.2f}'.format) = 소수 2번째 자리까지만 표기하겠다.

ㅇ df.columns = column명 반환

ㅇ unique( ) = 열(시리즈)의 고윳값

ㅇ value_counts( ) = 열의 고윳값 빈도

ㅇ sort_values( ) = 정렬(default : 오름차순)
sort_values(ascending=False) = 내림차순
2-3 시각화 :
ㅇ 시각화 시작 시 항상 해야 하는 첫 코딩 :

ㅇ DataFrame의 하나의 열 = series
→ type(df['노출수']) column title 한 개의 type을 입력해 보면

ㅇ 즉, 하나의 column title을 시각화 = series 시각화한다

ㅇ (위 그래프 너무 보기 힘듦..) → 명확한 패턴이 보일 수 있도록 다른 데이터 시각화 진행 :
(1) as-is : index를 기준으로 출력(그래프의 x축이 시리즈의 인덱스)
(2) to-be : 정렬된 value를 기준으로 출력
(2-1) 시리즈의 value를 수치 순서대로 오름차순 정렬하기
(2-2) 정렬된 데이터의 형태대로 index 재생성 후 시각화
# 위 그래프는 index기준으로 출력,
패턴을 더 잘 보이게 하기 위해 정렬된 value를 기준으로 출력하려 함.
(2-1) 시리즈의 value를 수치 순서대로 오름차순 정렬하기 : sort_values( )
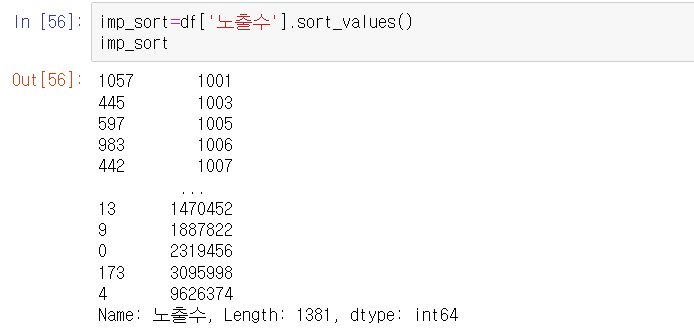
(2-2) 정렬된 데이터의 형태대로 index 재생성 후 시각화하기 :
ㄴ reset_index( ) 함수 = 인덱스 재생성! (기존 인덱스를 dataframe의 열로 반환)

ㄴ drop('삭제할 인덱스명', axis=1) = 기존 인덱스 삭제 + 열 기준으로 삭제

ㄴ 아닛.. 확인하려 다시 imp_sort 원본을 입력했더니 없앤 인덱스가 살아있다..! :
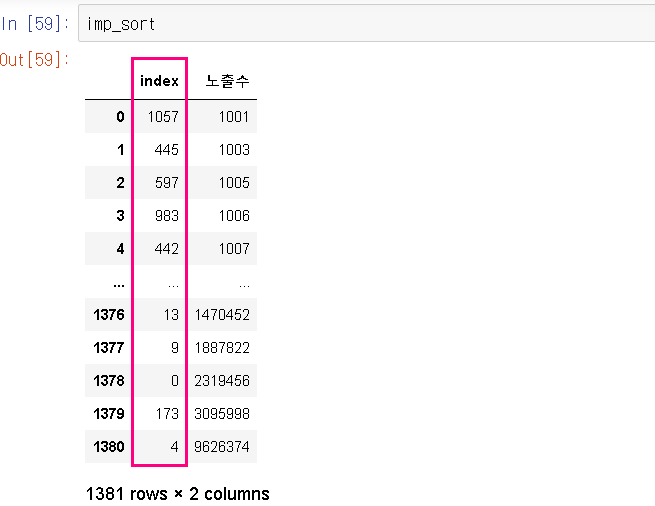
ㄴ inplace=True = 원본에도 적용하는 함수!
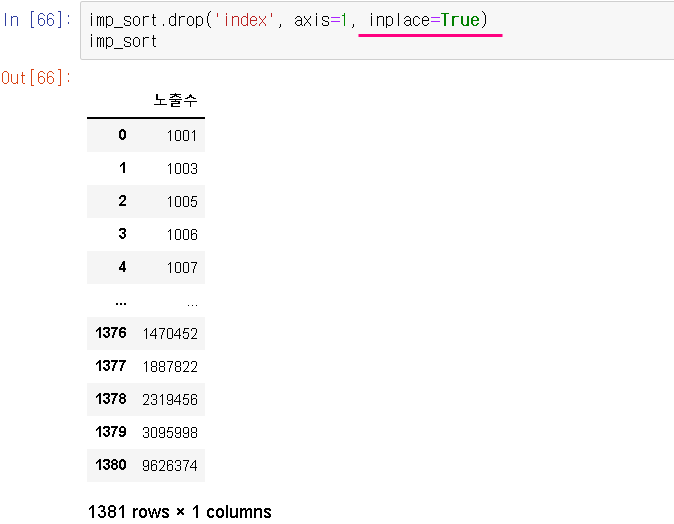
ㅇ '노출수' 열 시각화

ㅇ 위와 같은 목적이지만 한 줄로 해보기 : '클릭수' 열 시각화

ㅇ 위와 같은 목적이지만 한 줄로 해보기 : '총비용' 열 시각화
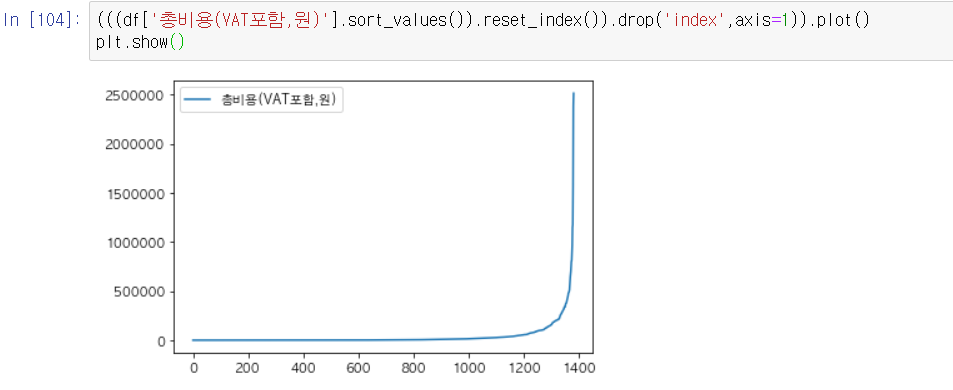
2-4 데이터 분석 :
ㅇ 노출수, 클릭수 기준 상위 5%에 해당하는 키워드 추출하는 방법 :
1. 95백 분 위수 찾기(quantile 함수 사용)
2. 95백 분 위수 이상(상위 5%)의 노출수 추출
3. 상위 5%에 해당하는 키워드 추출
1. 95백분 위수 찾기(quantile 함수 사용)
# 노출수 = impression == imp
# quantile( ) = 분위수 출력 (default : 2 사분위수 == 중앙값)

# quantile(0) = 최솟값 (= imp.min( ))
quantile(1) = 최댓값 (= imp.max( ))

2. 95백 분 위수 이상(상위 5%)의 노출수 추출
# imp.quantile(0.95) = 95 백분위수
imp[imp >= imp.quantile(0.95)] = 95 백분위수 이상

# 95 백분위수 이상을 → 'imp'로 새로 명명해주기 :

3. 상위 5%에 해당하는 '키워드' 추출
- 기존 상위 노출수 추출과정 :
(1) as-is : 데이터 프레임의 기본 숫자 인덱스
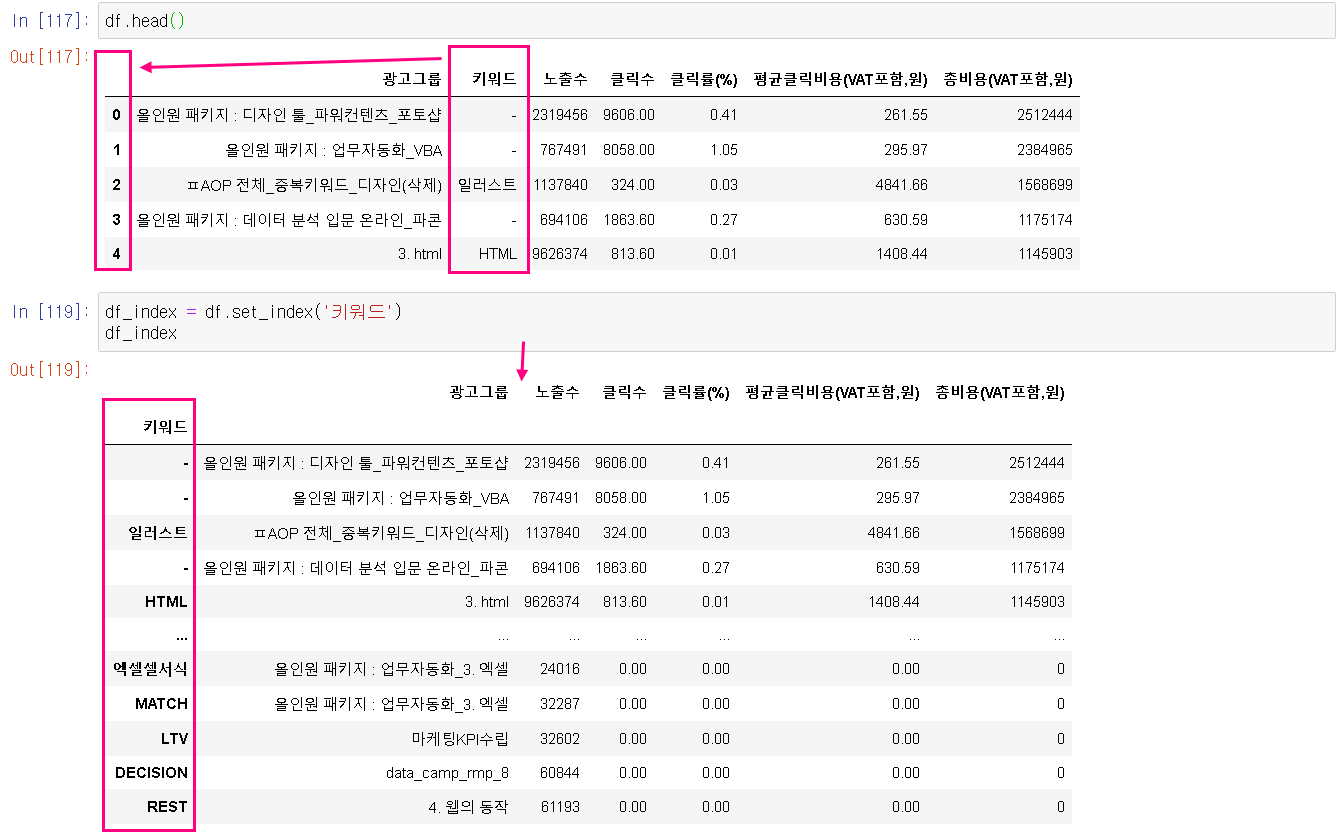
(2) to-be : 데이터 프레임의 인덱스를 '키워드'로 재설정
# 기존 테이블의 인덱스(0, 1, 2, ...)를 → '키워드'로 대체 (재설정) :
set_index(' ')
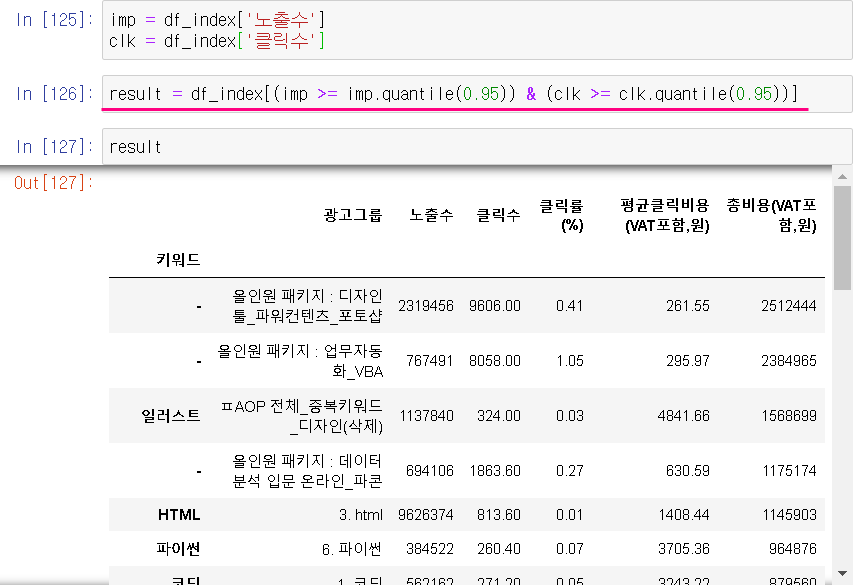
# 노출수, 클릭수의 상위 5%(=0.95 이상) 출력 :

ㅇ 조건이 여러 개일 경우 : 데이터프레임[(조건문)&(조건문)]
# 한 번에 출력 + 'result'로 명명해준 것
result = df_index[(imp >= imp.quantile(0.95)) & (clk >= clk.quantile(0.95))]
# 조건을 다 만족한 result의 index 출력하기 :

ㅇ 노출수, 클릭수 기준 상위 5%의 키워드가 아닌데도 불구하고 비용이 많이 쓰이고 있는 키워드가 있다 :
ㄴ 위에 시각화한 그래프들 보면 :
1. 노출수 95백 분 위수 미만
2. 클릭수 95백 분 위수 미만
3. 총비용 85백 분 위수 이상
4. 총비용 95백 분 위수 미만
e.g.

# 조건을 다 만족한 result의 index 출력하기 :
# 조건에 맞는 저효율 키워드 출력하기 :

2-5 광고그룹 분석 :
ㅇ groupby함수 사용 실습 :
# as-is : 키워드 기준 분석
→ 키워드의 노출수/클릭수/총비용...
# to-be : 광고그룹 기준 분석
- 데이터의 구성을 광고그룹 기준으로 변경해야 함
- 광고그룹의 노출수/클릭수/총비용...
- groupby 함수 사용
# .groupby( ) = 전달된 열을 기준으로 전체 데이터를 분류

# count( ) = 각 광고그룹 데이터의 개수
mean( ) = 각 광고그룹 데이터의 평균
median( ) = 각 광고그룹 데이터의 중앙값
std( ) = 각 광고그룹 데이터의 표준편차
var( ) = 각 광고그룹 데이터의 분산





2-6 광고그룹 기준 데이터 전처리 :
ㅇ 그룹데이터의 합계(sum) grouped.sum( )으로 변수 출력 → 노출수, 클릭수, 총비용 열
# '키워드'에 대한 각 합계 but '클릭률', '평균클릭비용', '총비용' → 광고그룹에 대한 합으로 바꿔야 함

# 그룹 데이터 합계를 df_group 변수로 출력해서 전처리를 한다!

# 데이터 전처리 = 데이터 프레임의 열 단위로 수치 연산
# 클릭률(ctr) = 클릭수 / 노출수 → 변수: df_group['클릭률(%)']
# 평균클릭비용(cpc) = 총비용 / 클릭수 → 변수: df_group['평균클릭비용(VAT포함,원)']


# 추가적으로, 평균클릭비용이 기존 데이터 : 소수점이 있음
ㄴ 반올림처리(round) + 소수점 제거(astype(int)) 해주기 :

2-7 데이터 시각화 :
ㅇ 노출수 열 → 선 그래프

ㅇ 어우... 위 그래프 너무 지저분하기 때문에, 명확한 패턴이 보일 수 있도록 데이터 시각화 진행하기 :
1. as-is : index를 기준으로 출력(그래프의 x축이 시리즈의 인덱스)
2. to-be : 정렬된 value를 기준으로 출력
2-1. 시리즈의 value를 수치 순서대로 오름차순 정렬
2-2. 정렬된 데이터의 형태대로 index 재생성 후 시각화
# 한 줄 사용 시각화 (노출수, 클릭수, 총비용) :


ㅇ 중점관리 광고그룹
# 상위 20%(노출수 80백 분 위수 이상) & 상위 10%(클릭수 90백 분 위수 이상) :

ㅇ 저효율 광고그룹 : 노출수, 클릭수 기준 상위의 키워드가 아닌데도 비용이 많이 쓰이고 있는 광고그룹
# 노출수 80백 분 위수 미만
# 클릭수 90백 분 위수 미만
# 총비용 60백 분 위수 이상
# 총비용 90백 분 위수 미만

print('to be continued...')
'공부zip. > 데이터사이언스' 카테고리의 다른 글
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 4.2 (0) | 2022.03.26 |
|---|---|
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 3.3 (0) | 2022.03.23 |
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 3.2_(데이터 불러오기-구경하기-비교하기-시각화하기) (0) | 2022.03.18 |




댓글