이번엔 kaggle에 관하여 배워보았고, 이를 가지고 데이터를 분석해보았다.
목차.
- 필요한 라이브러리 불러오기
- Kaggle Survey 데이터 불러오기
- 데이터 전처리
- 교육수준과 관련된 EDA
- 직업과 관련된 EDA
- 한국에 있는 사람들은 어떨까?
사용한 Kaggle Data :
https://www.kaggle.com/c/kaggle-survey-2020/data
2020 Kaggle Machine Learning & Data Science Survey
www.kaggle.com
EDA를 할 것이기 때문에 2020 kaggle survey를 통해 실제로 kaggle에서 활동하는 사람들, 대략 2만 명(더 많았겠지만 그중 유의미한 데이터 2만 개)의 실제 설문조사 데이터를 가지고 참여한 사람들이 어떤 특징을 갖는지 알아보는 것.
Log-in > 왼쪽에 Compete > scroll down > 'All Competitions' > Completed > 2020 Kaggle Machine Learning & Data Science Survey > 상단에 Data
3가지 데이터가 있음 :
1) Main Data → csv 파일
2) Supplementary Data 1
3) Supplementary Data 2
목적 - 데이터를 통해 알아보고 싶은 것 :
1. education status - kaggler들이 어떤 education status를 갖고 있는지
2. job status - kaggler들이 어떤 직업군이며 어떤 일을 하는지
1. 필요한 라이브러리 불러오기 :
ㄴ 이제 외워야 함.. ^^
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns

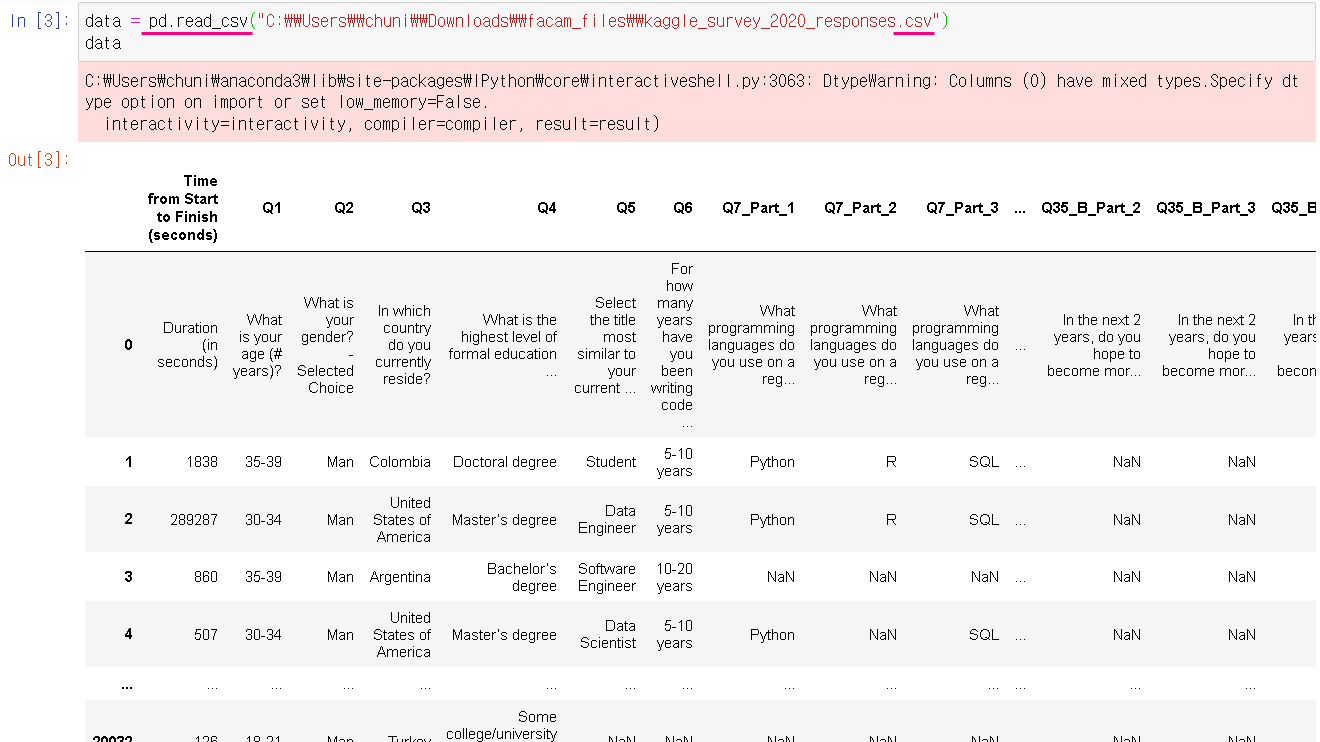
2. Kaggle Survey 데이터 불러오기 :
ㅇ pd.read_csv(" .csv") 함수
ㅇ 질문 row를 맨 위에 올리는 방법 :
= header=1 추가해주기

# 문제는 질문이 너무 길어서 원래대로 사용하는 게 보기엔 편할 듯!
3. 데이터 전처리 :
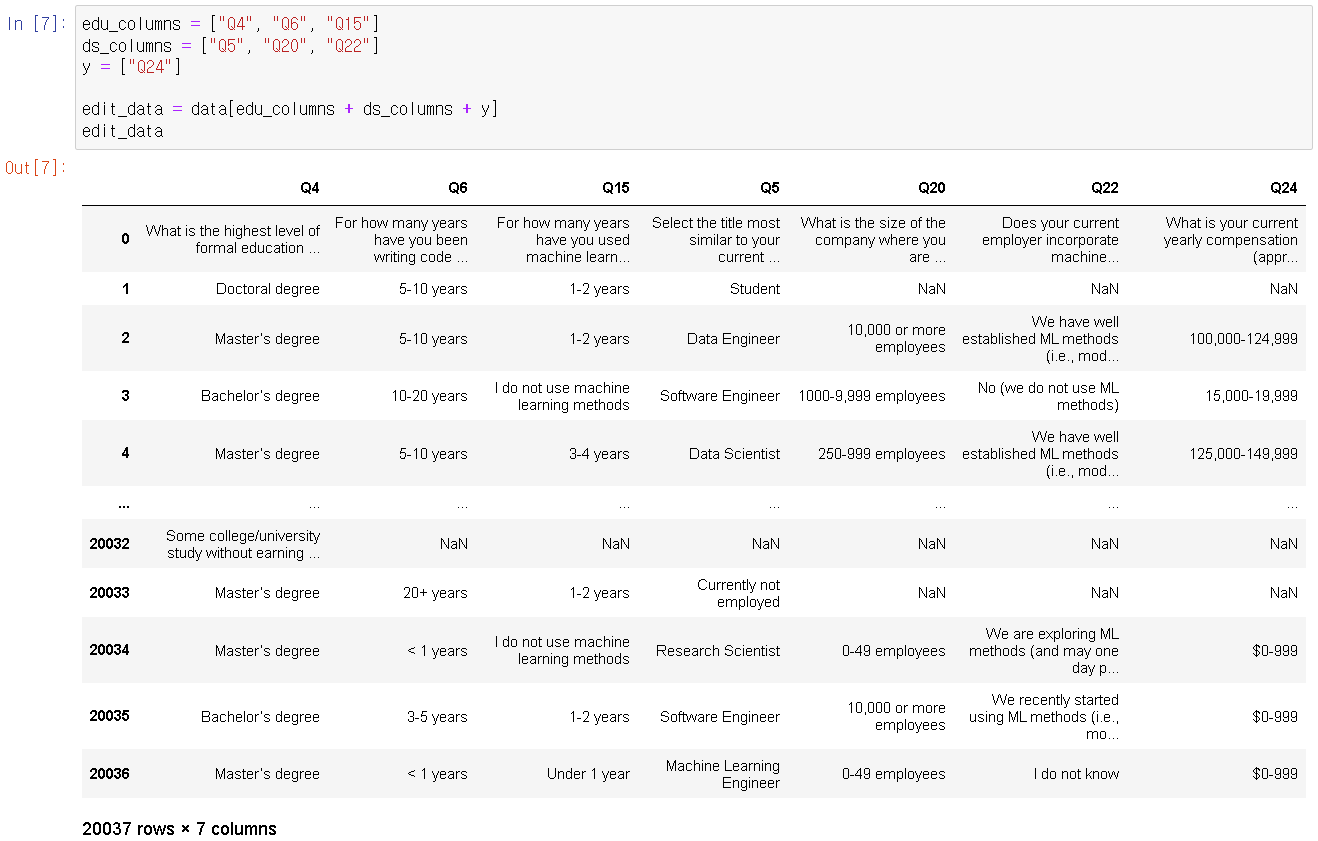
ㅇ education status(교육상태)와 관련 있는 column들 & Data Science 실무 경력과 관련된 column들을 고른다
# Supplementary Data pdf 파일에서 어떤 Q이 education status인지, job status 데이터인지 확인 가능
# 데이터 추려내기 (명명도 해줌) :
edu_columns = ["Q4", "Q6", "Q15"]
ds_columns = ["Q5", "Q20", "Q22"]
y = ["Q24"] → y축
edit_data로 위 3가지 데이터들 묶어버리기
# null값 제외한 행만 추출하기 :
edit_data.isnull( ).any( )
any( ) 함수 = 어떤 축을 기준으로 true가 하나라도 있으면 true를 나타내 줌

# masking을 해주면 :

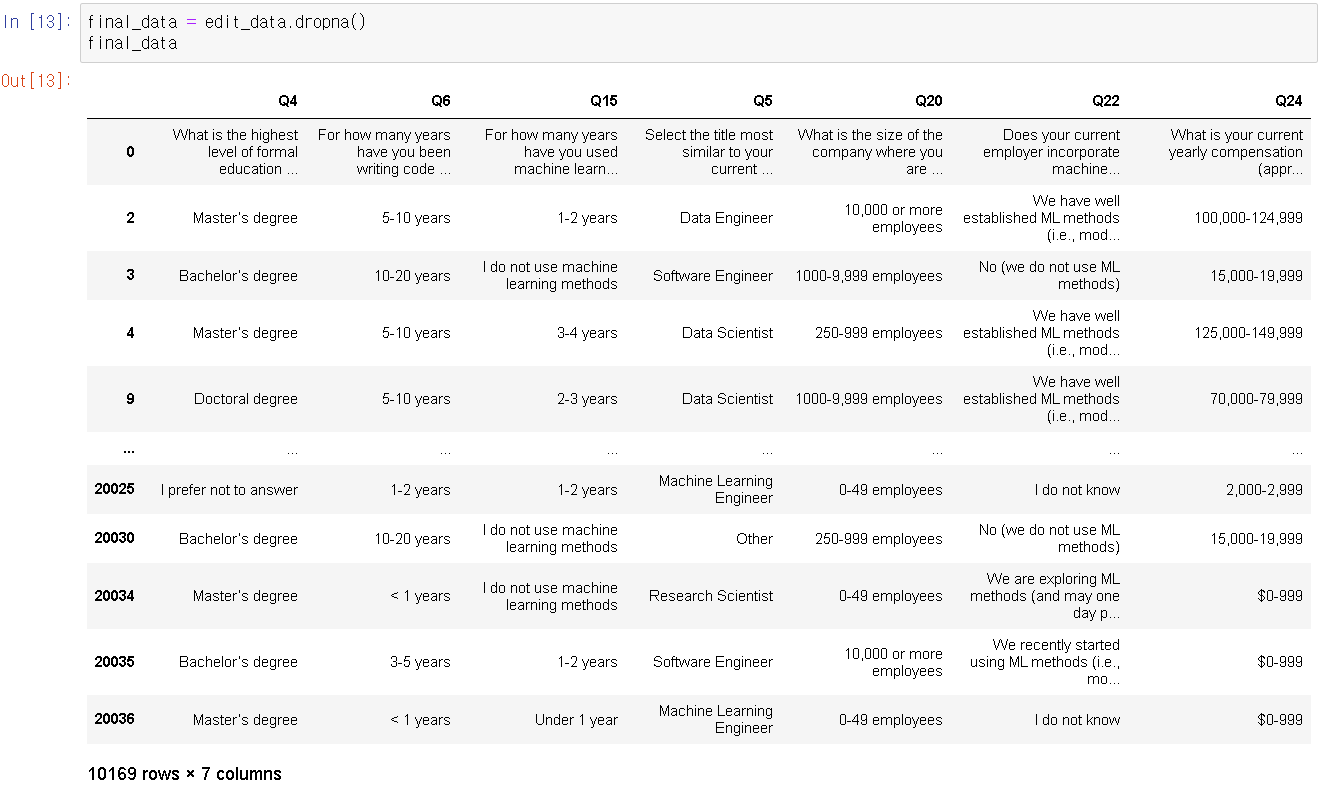
# 결측치 제거하기 :
final_data = edit_data.dropna( )
3-1. 교육 수준과 관련된 EDA :
ㅇ EDA에서 살펴볼 항목 :
- 기본적인 빈도 분석
- 히스토그램
- Pie chart과 같은 plotting 기법들
ㅇ Q4 column : "What is the highest level of formal education that you've attained/plan to attain within the next 2 years?"
# [1:] → slicing을 해줌으로써 제일 위에 있던 질문란이 없어지고 데이터만 남게 됨!

> 기본적인 matplotlib(pyplot)을 이용하여 시각화 하기 :
# histogram으로 불러오기 :
plt.figure(figsize=(16, 16))
plt.title("Histogram of Q4 column")
plt.hist(Q4)
plt.show()

# pie chart/graph로 불러오기 :
plt.figure(figsize=(16, 16))
plt.pie(Q4.value_counts(), → value_counts( ) 함수 = 내림차순 순서대로 해줌
labels=Q4.value_counts().index,
autopct='%d%%',
startangle=90,
textprops={'fontsize':12})
plt.axis('equal')
plt.title("Pie chart for Q4 column", fontsize=16)

ㅇ Q6 column : "For how many years have you been writing code and/or programming?"
> 반복

# histogram으로 불러오기 :
plt.xticks(rotation='vertical') → 해주면 x축 label들이 세로로 바뀜 (레이블이 길 때 유용!)

# pie chart/graph로 불러오기 :
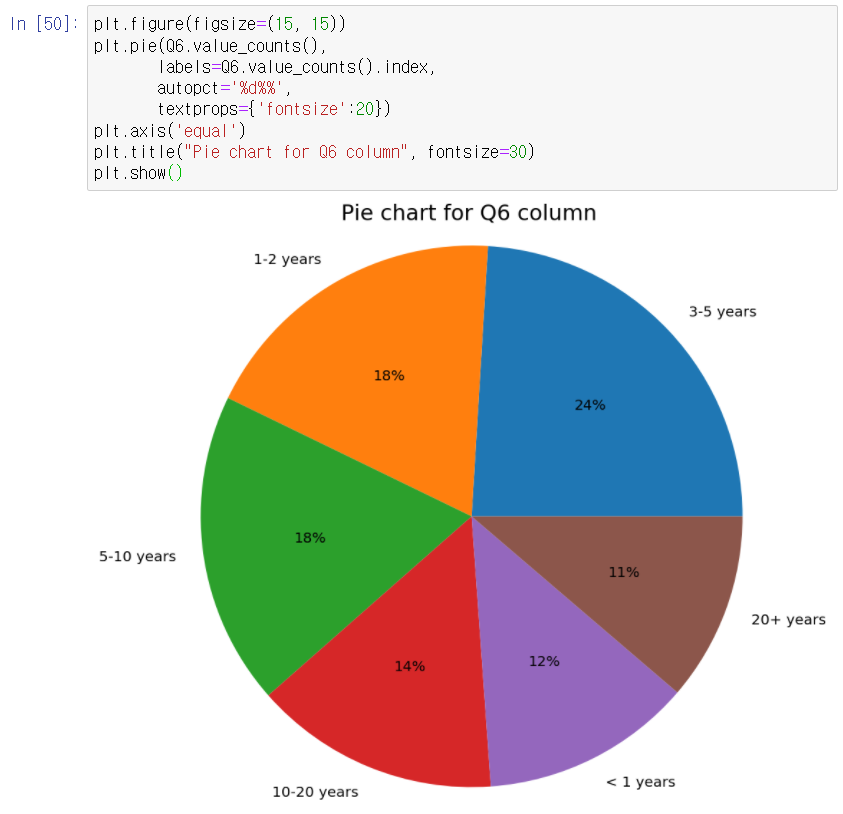
ㅇ Q15 column : "For how many years have you used machine learning methods?"

> seaborn을 이용하여 시각화 하기 :
# histogram으로 불러오기 :
sns.countplot( ) 함수

# x축으로 돌렸을 때 깨져서, 직접 plt.figure, plt.xticks를 추가했다~ (기억력 짱짱 ㅎ)

ㄴ under 1yr이 가장 많고 그만큼 kaggle에 뛰어드는 사람들이 많다는 걸 알 수 있음
# pie chart/graph로 불러오기 :

3-2. 직업과 관련된 EDA :
ㅇ EDA에서 살펴볼 항목 (repeat reminder^^):
- 기본적인 빈도 분석
- 히스토그램
- Pie chart과 같은 plotting 기법들
ㅇ Q5 column : "Select the title most similar to your current role"

> 기본적인 matplotlib(pyplot)을 이용하여 시각화 하기 :
# histogram으로 불러오기 :

# 위 그래프를 내림차순으로 예쁘게 정리하고 싶다면 :
# bar chart/graph로 불러오기 :
plt.bar(Q5.value_counts( ).index, Q5.value_counts( ).values) 함수를 hist( ) 함수 대용

# pie chart/graph로 불러오기 :

ㅇ Q20 column : "What is the size of the company where you are employed?"
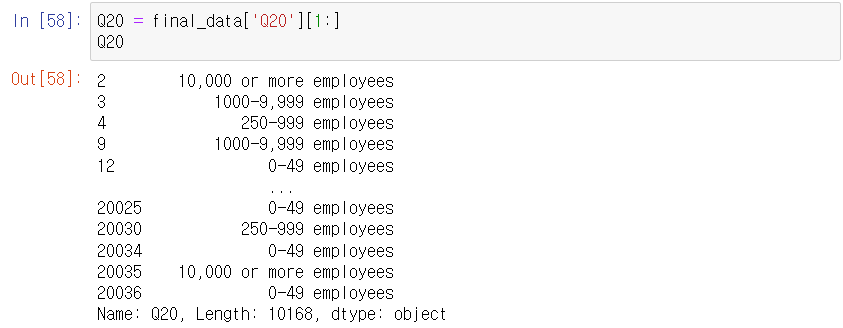
> seaborn을 이용하여 시각화 하기 :
# histogram으로 불러오기 :
# pie chart/graph로 불러오기 :

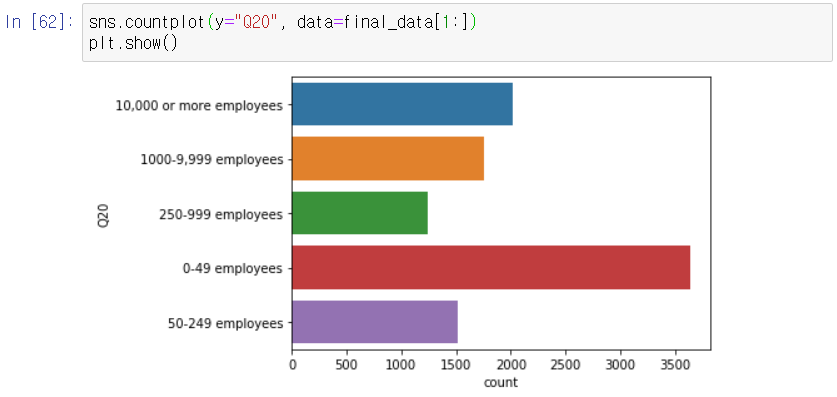
ㅇ Q22 column : "Does your current employer incorporate machine learning methods into their business?"

# 정답을 알려줘~ :

> seaborn을 이용하여 시각화 하기 :
# histogram으로 불러오기 :
bar chart를 horizontal 하게 : plt.barh( )
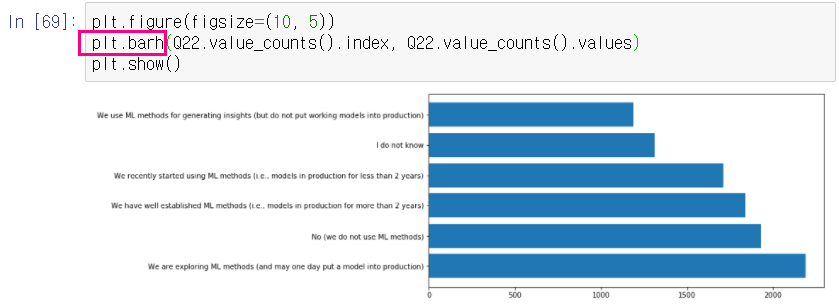
# pie chart/graph로 불러오기 :

4. 한국에 있는 사람들은 어떨까? :
# Q3 : In which country do you currently reside?
→ 여기서 한국을 찾을 수 있다!
set(data['Q3']) 로 나열하여 찾을 수 있음 == 'Republic of Korea' / 'South Korea'

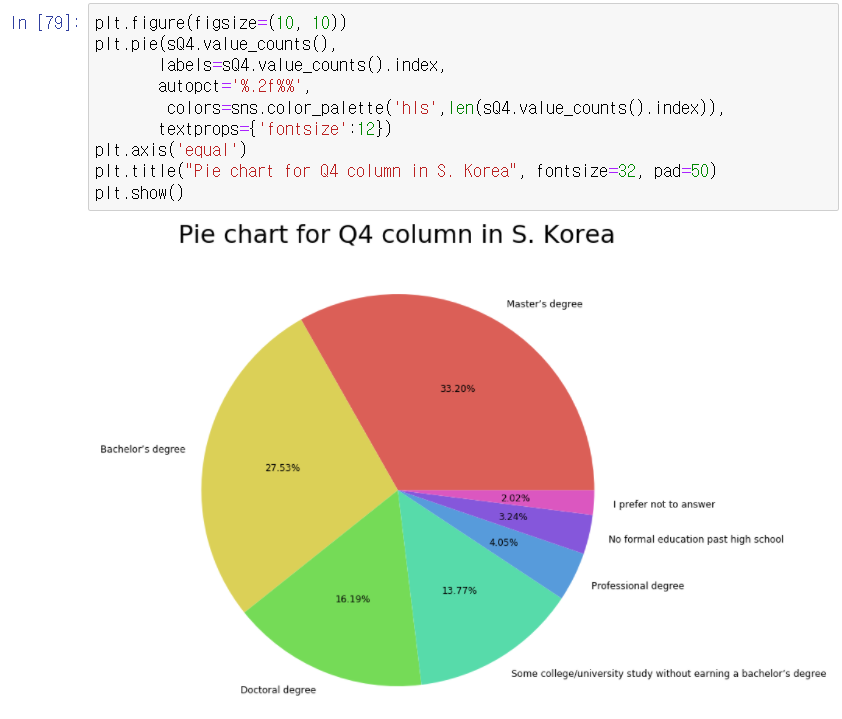
ㅇ Q4 column : "What is the highest level of formal education that you've attained/plan to attain within the next 2 years?"
# skorea로 명명을 먼저 해준다
# sQ4로 또 명명을 해주고 답변들의 수를 확인해본다

# histogram으로 불러오기 :

# pie chart/graph로 불러오기 :
'공부zip. > 데이터사이언스' 카테고리의 다른 글
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 4.1 (0) | 2022.03.25 |
|---|---|
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 3.2_(데이터 불러오기-구경하기-비교하기-시각화하기) (0) | 2022.03.18 |
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 3.1 (0) | 2022.03.17 |




댓글