2주 차 강의.

2주 차 강의는 양이 꽤 많았다.. 이렇게 차이나도 돼..?
처음이라 꼼꼼하게 봐서 그런지 오래 걸렸던 것 같다.
이제 본격적으로 파이썬 프로그래밍을 시작!
2주 차가 Python(1, 2, 3, 4)로 나뉘어 있는데, 양이 너무 많아서
두 번 나눠서 올릴 예정이다.

오늘의 개발 노트.
목차.
- Computer Architecture & Programming
- Programming이란
- Computer Architecture
- 왜 파이썬일까
- Python Data Types
- Data Type이란
- 변수(Variable)란
- 숫자 데이터(Numberical Data Types)란
- 정수형(Integer)
- 실수형(Floating Point)
- 산칙연산
- 특수연산
- 문자열(String)이란
- 연속형 데이터(Sequential Data Types)란
- 리스트(List)
- 슬라이싱(Slicing)
- 튜플(Tuple)이란
- 집합(Set)이란
- 사전(Dictionary)이란
1. Computer Architecture & Programming
- Programming이란 :
= 컴퓨터에게 일/명령을 내리는 과정/방법이며 결과로 하나의 과정을 수행하는 '프로그램'이 생성된다.- 2 가지 구성 요소 필요 : 1) 프로그램을 하수행 하는 컴퓨터와 2) 명령을 구성하는 코드
- 컴퓨터와 소통하는 것 = 코드를 통해 프로그래'밍'을 함
- Computer Architecture :
- CPU = 컴퓨터에 일어나는 모든 계산을 처리하는 애
- RAM = 중간에서 데이터를 가지고 CPU와 일하는 애
- SSD = 모든 데이터를 저장하고 있는 애 (장점: 데이터를 많이 갖고 있을 수 있음)
# RAM이 있는 이유: CPU-빠르지만 용량 작음-가 100만 번 일할 때 SSD-느리지만 용량 큼-는 한 번 일함. 즉, CPU가 답답할 수밖에... > 그 중간인 DRAM 필요. - 왜 파이썬일까?
= 전 세계적으로 가장 많이 사용하는 프로그래밍 언어 중 하나.
# Zen of Python(PEP 20) 파이썬의 기본적인 철학이 담겨있음
ㄴ '파이썬은 기본적으로 예쁘고 깔끔해야 한다'가 디폴트 (=가독성이 좋아야 한다.)- 메인 특징 :
1) 생산성 : 개발 속도가 빠름
2) 가독성 : 코드가 예쁘고 보기 편함
3) 확장성 : 오픈소스 라이브러리
ㄴ 쉽게 사용할 수 있는 소스들이 많이 공개되어 있기 때문에 빠르게 발전할 수 있었다고 함. - 파이썬 프로그래밍 언어 - 비교적 특징들 :
- interpreter 언어 = 한 줄씩 실행함, 코드를 부분 부분 진행 가능
- 동적인 데이터 타입 지원 = 데이터를 보며 '이건 숫자, 저건 문자' > 자동으로 지정함
- 간단하고 쉬운 문법 (상대적으로)
- 높은 확장성 (=오픈소스 라이브러리)
- 다양한 데이터 타입
- 메모리 자동 관리
# 오픈소스 라이브러리가 아니더라도 다른 사람이 만들어 놓은 코드도 공개가 많이 되어 있음 @github - 파이썬에서 프로그래밍을 할 때 지켜야 되는 규칙 :
1) 띄어쓰기, 들여 쓰기(tab) 꼭 지키기!
2) 변수의 type(문자/숫자 등)를 따로 지정하지 않아도 됨!
3) line by line으로 차례대로 실행됨!
- 메인 특징 :
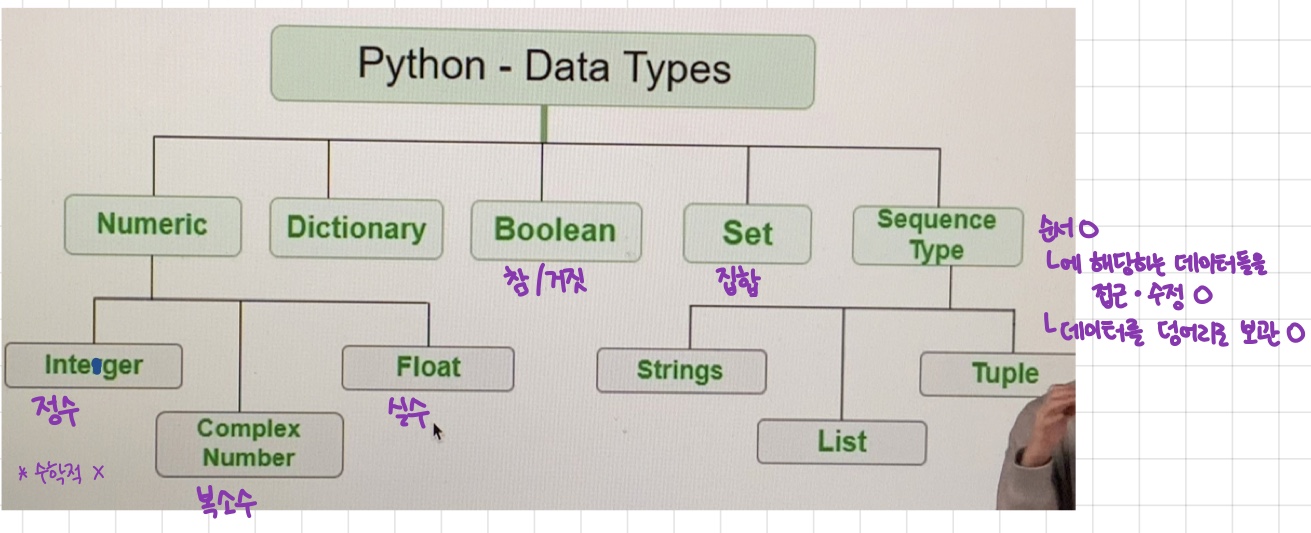
2. Python Data Types
- Data Type이란 :
= 모든 프로그래밍 언어가 데이터를 다루기 위해 필요한 약속.- 프로그래밍 언어마다 조금씩 다르며, 시작할 때 제일 먼저 익혀야 하는 필수 관문.
- 프로그래밍 언어에서는 변수에서 데이터를 저장/관리함.
ㄴ '변수'라는 개념을 통해 데이터를 사용할 수 있다. - 중요한 포인트는 : 어떤 연산을 사용할 수 있는지 + 연산 결과가 어떤 의미인지를 알아야 함.
- 변수(Variable)란 :
= 메모리에 데이터를 저장하기 위한 공간 + 컴퓨터와 프로그래밍 언어 사용자 간의 약속- nickname 느낌
- 실제 물리적인 메모리 주소 공간을 가리킴
ㄴ 사용자 : 변수의 이름으로 데이터 인식
ㄴ 컴퓨터 : 변수의 주소로 데이터 인식
- 숫자 데이터(Numberical Data Types)란 :
= 정수/실수/복소수/2진수/8진수/16진수를 포함하며 가장 많이 사용하는 데이터 타입 중 하나.
- 파이썬 숫자 표현 범위 : 무한대
- 숫자 데이터는 우리가 알고 있는 대부분의 연산을 그대로 지원함 (사칙연산, 나머지 구하기, 몫 구하기 등)
> 정수형(Integer) :

> 실수형(Floating Point) :

- 숫자형 데이터 타입이 제공하는 여러 연산자 :
> 사칙연산 :

> 특수 연산 :

print(c ** d) : c를 d번 곱하다
print(c // d) : c를 d로 나눈 몫
print(c % d) : c를 d로 나눈 나머지
== : 같다
!= : 다르다
N % 4 == 0 : 4의 배수(=N을 4로 나눈 나머지가 0일 때)
> 문자열(String)이란 :
= character sequence(문자의 나열) e.g. "Hello world"
ㅇ 문자열을 만드는 여러 가지 방법 :

-
- 특징 :
- 파이썬에서 다룰 수 있는 문자열의 크기 : 무제한
- ' ', " " -> 두 가지의 기호를 통해 문자열 나타냄
- 현재 전 세계적으로 웹에서 사용되는 국제 표준 : UTF-8
- 컴퓨터 문자를 encoding 하여 숫자로 표현함 e.g. ASCII, cp949...
ㄴ 컴퓨터는 문자 > 숫자로 인식함
- 특징 :
1. 원래 한 줄에 써야 하지만, 나는 꼭 엔터를 치고 싶다! :


2. 특수 문자 표현(escape code) :
\n (원래 '/' 반대 모양) = new line
\t = tab

3. 문자열 계산하기 :
(1) 가운데에 빈칸 넣기 :


(2) 반복해서 출력하기 :

(3) 문자열 길이 출력하기 : 함수 len( )

4. 문자열 Formatting : [스스로 생각해내서 만들기엔 연습 필요..]
= 문자열 출력할 때(print 함수 이용) 특정 format을 지정하고 싶은 경우 :
1) print format = print("%s는 %d개 있다." % (A, B))
[ %s = A / %d = B ]
2) str.format = print("{ }는 { }개 있다." .format(A, B))
3) f-string = print(f"{A}는 {B}개 있다.")

5. 문자열 관련 함수들 :
1) 대소문자 = s.upper( ), s.lower( )

2) 문자 공백 지우기 = s.strip( )
- 맨 왼, 오른쪽 공백만 없어짐

3) 문자열 삽입 = "무언가". join("abcd")
- 무언가를 "abcd" 사이에 각각 삽입

4) 문자열 나누기 = s.split( )


5) 문자열 바꾸기 = s.replace("A", "B") -> s의 A를 B로 바꿔라

> 연속형 데이터(Sequential Data Types)란 :
= 하나의 변수에 여러 개의 데이터를 넣을 수 있음
= List, Tuple, String이 해당됨
ㄴ 각 연속형 데이터 타입마다 특징이 다름
- 그 특징을 파악하여 용도에 맞는 데이터 타입 사용하는 것이 중요하다
- 구분해야 할 부분 (동일한 연산/operation 사용 ㅇ) : indexing & slicing
- 이 두 가지가 되면 연속형 데이터 타입이 됨.
1. 리스트(List) :
= 가장 많이 사용되는 연속형 데이터 타입!
- 굉장히 유연한 구조를 가지고 있어 데이터를 편하게 다룰 수 있음
- 파이썬에서 [ , ]를 이용하여 표현함 -> [1, 2, 3]
- 리스트의 원소 : 쉼표로 구분, 아무 데이터 타입 가능, 리스트조차 가능!
- 수정이 자유로움 (수정을 하면 안 되는 경우에는 사용 x)
1.1 리스트 만드는 방법 :
# type(변수) -> 실행하면 변수가 어떤 데이터 타입인지 알려줌




1.2 인덱싱(Indexing) :
= '어디'에 있는 '어떤 데이터'를 찾겠다.
- 연속형 데이터들은 one 변수에 여러 가지 데이터를 가지기 때문에, 여러 데이터를 접근하는 방법이 필요
- 리스트의 index는 맨 앞부터 0으로 시작해, 1씩 증가하는 정수 index 사용 (#index 0!)
e.g. [1, 2, 3] 일 때, 원소 [1: 0, 2: 1, 3: 2]
- 음수 index도 제공 -> 맨 뒤에서부터 왼쪽으로는 -1, -2... (0은 -0이 없기 때문에 -1에서 시작)
- index 사용 법 :
e.g. L = [1, 2, 3] 일 때, L[0] = 1, L[-1] = 3


1.3 인덱싱 그냥 외우는 것보다는 이렇게 이해하자! :


1.4 슬라이싱(Slicing) :
= 리스트의 일부만 잘라내서 사용하고 싶을 때 쓰는 기법 (인덱싱을 범위로 하는 느낌)
- 리스트의 index & : 을 사용하여 슬라이싱



1.5 리스트 연산하기 :

1.6 리스트 관련 함수 :
- L.append( ) = 리스트에 원소 추가하기

- L.sort( ) = 리스트 원소 오름차순 정렬
L.sort(reverse=True) = 내림차순 정렬


- L.reverse( ) = 리스트 뒤집기 (정렬 X)
ㄴ slicing으로 가능한 또 다른 방법 = L[ : : -1 ] = 처음부터 끝 범위에서 뒤에서 앞으로 출력


- L.pop( ) = 리스트에서 가장 늦게 들어온 원소 한 개 제거하기
ㄴ 원하는 원소를 (순서와 상관없이) 제거하고 싶을 때는 : L.remove( ) 사용하기!

> 튜플(Tuple)이란 :
= 리스트와 비슷함
- indexing, slicing 동일하게 사용 가능
- 원소들도 자유롭게 사용 가능
리스트 vs 튜플 차이점 2가지 :
| 사용하는 괄호 | 생성 후 수정 가능성 | Data Type | |
| 리스트 | [ ] | O (Mutable) | Mutable: List, Dict, Set |
| 튜플 | ( ) | X (Immutable) | Immutable: Int, Float, String, Tuple, Frozenset |
ㄴ Immutable Data Type이 필요할 때가 있음 :
1) 성능적인 이슈 -> 데이터가 변경되지 않아서 그 자체로 장점
2) 프로그래밍적인 이슈 -> 데이터 수정 자체를 x, 실수 방지

> 집합(Set)이란 :
= 수학 집합과 (=)
- 수학: { } 사용 / 파이썬도 { } 사용하지만, 그냥은 x
- 사전(dict) 자료형도 { } 사용하기 때문
ㅇ 공집합 : set( ) -> { }이걸 쓰면 빈 사전이 생성된다.
ㅇ 집합의 연산자 : 교집합, 합집합, 차집합 모두 지원
ㅇ 특징(리스트와 차이점) :
1) 집합은 원소의 중복이 X (원소의 종류를 나타내기에 좋음)
2) 집합은 원소의 순서가 X (원소의 index가 X)

ㅇ 집합의 연산 :
1) 교집합 = s1 & s2
2) 합집합 = s1 | s2 or s1.union(s2)
3) 차집합 = s1 - s2 or s2 - s1
ㄴ 순서에 따라 구하는 값이 다름




> 집합의 원소의 uniqueness를 활용하는 경우 :

> 집합 관련 함수 :
s.add( ) = s집합에 원소 하나 추가

s.update( ) = s집합에 여러 원소 추가
!= s.union( ) = 출력은 같지만, 아예 새로운 집합이 생김

s.remove( ) = s집합에서 원소 제거

> 사전(Dictionary)이란 :
= 파이썬에서 리스트와 함께 굉장히 많이 사용되는 구조!
= 데이터 타입 중 가장 powerful + 신기함 + 많은 활용 용도를 갖고 있음
- 파이썬에서 제공하는 사전 자료형 : key - value 방법을 통해 저장함
- 엑셀에 table 만드는 것처럼 table concept을 의미함
ㄴ 정수 index가 X, key값을 통해서 value를 access 한다!
(특정 이름/번호 등 데이터를 지칭할 수 있는 값인 key를 세팅
-> 내가 원하는 데이터를 value에 넣고
-> key값들을 통해 접근이 가능하다 = 몇 번째인지 몰라도 이름/번호로 찾을 수 있다)
ㅇ 전문 용어 : Hash Table

ㅇ 파이썬에서 사전 자료형 : { } 이용
ㄴ 집합(set)과 차이를 두기 위해 원소에 반드시 : 가 들어감
ㄴ 사전 표현 : {'key' : 'value', 'key2' : 'value2', ...}
ㅇ 사전 만드는 방법 :

# 인덱싱을 했을 때 이미 있으면 수정, 없으면 생성됨 :

# 사전을 만들 때 key는 중복이 있으면 안 된다. (중복되면 하나만 남기고 나머지 사라짐)
# 집 주소라 생각해보자. 주소는 중복이 되면 안 되고, 마음대로 바꿀 수도 없다!

ㅇ 사전 관련 함수 :
D.keys( ) = 사전의 모든 key값들 보기

D.values( ) = 사전의 모든 value들 보기

D.items( ) = 사전의 모든 key, value 쌍 보기

D.get('key값') = 사전의 원소 가져오기
ㄴ key값이 존재할 때 & 존재하지 않을 때
D.get('key값', '지정 key값') = 만약 입력한 'key값'이 존재하지 않는다면 새로 '지정 key값'으로 저장하게 됨


# '~' in D = '~' in D.keys( ) 사전에 해당 key값이 존재하는지 확인하기
ㄴ in이라는 operator는 사전뿐만 아니라 모든 연속형 데이터 타입에 사용 가능
ㄴ 사전의 경우 : 해당 원소가 존재하는지 True/False를 알려줌!
# '~' in D.values( ) = 사전에 해당하는 value값 존재하는지 확인

공부할 걸 토대로 [Programming Practice] 연습 문제를 풀었다.
막상 혼자 처음부터 적어보려니까 굉장히,, 뭐랄까, 뭐부터 써야 될지 모르겠네...
코린이 탈출할 수 있겠쥬.....?
파이팅..!⭐
print("to be continued...")'공부zip. > 데이터사이언스' 카테고리의 다른 글
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 3.1 (0) | 2022.03.17 |
|---|---|
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 2.2 (0) | 2022.02.25 |
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 1 (0) | 2022.02.25 |




댓글