2주 차 강의_continued.

목차.
- Control Statement : Conditional Statement(If)
- Control Statement이란?
- If Statement
- 연습
- Control Statement : Iteration Statement(While, For)
- Iteration Statement이란?
- While statement
- For statement
- Function
- Function -- Definition
- Function Implementation(응용)
- Lambda Function
- 파이썬에 '이미' 정의 되어 있는 함수들 사용해보기
- 데이터 입출력(Input / Output)
- I/O란?
- stdin/out 사용하기
- file I/O 사용하기
- I/O Implementation
- Numpy
- numpy란?
- numpy array 특징
- numpy array 만들기
- numpy array 사용하기
2주 차 후기.
1. Control Statement : Conditional Statement(If)
- Control statement이란? :
= 프로그램의 흐름을 제어하는 명령어
ㄴ 컴퓨터가 어떤 일을 해야 하는지에 대한 과정.- 즉, 프로그래밍을 할 때 가장 중요한 건, 어떤 조건에서 어떤 것을 할 거냐.. 일을 얼마나 반복할 거냐?
= 조건과 반복의 나열이다. - 컴퓨터는 사람이 아니기 때문에 매우 구체적으로 과정을 알려줘야 한다.
이렇게 컴퓨터를 제어하려면 ‘제어문(Control Statement)’이 필요하다.- Conditional Statement, 조건문 (조건에 따라 판별) : if, elif, else
- Iteration Statement, 반복문 (반복을 수행) : while, for
- 사실상 프로그래밍 : 데이터를 사용자가 ‘원하는 대로’ 제어하여제어하여 ‘원하는’ 결과를 내는 과정을 말한다.
- 즉, 프로그래밍을 할 때 가장 중요한 건, 어떤 조건에서 어떤 것을 할 거냐.. 일을 얼마나 반복할 거냐?
- If Statement(조건문) :
= 프로그램에서 가장 중요한 조건 판단- if, elif, else
- if 조건문 모양 :
if 조건: (enter) 누르면 아래로 tab이 된 상태에서 내려감🔻
~~~~~~
~~~~
print(~~~)
# Jupyter에서 초록색으로 뜨는 단어들 : key/reserved word
(파이썬에서 사용하는 의미 있는 단어로, 변수로 사용 X) - 조건문 비교 연산 & 논리 연산 :
ㄴ 둘의 공통점 : 결과 가 참/거짓
a == b, a != b, a > b, a < b, a >= b, a <= b
#같다, 다르다, 크다, 작다, 크거나 작다, 작거나 같다
a and b #a와 b 둘 다 만족
a or b #a와 b 중에 하나 이상 만족
not a #a가 아닌 것
> 자판기 프로그래밍 연습 :
300원을 넣으면 : 커피
300원 < : 돈을 그냥 돌려줌
300원 > : 커피+거스름돈

> if - elif(else if) - else 구문 사용 연습 :

> nested 구조 이용하기 :
= 조건 안에 조건 (A가 아니면 B안에서 또 B-1이 아니면 B-2)

2. Control Statement : Iteration Statement(While, For)
- Iteration Statement(반복문)이란? :
= 비슷한 작업을 반복한다.
- 프로그램에서 가장 중요하다! 왜???
- 컴퓨터는 단순 작업의 반복에 최적화된 기계.
- 주어진 일을 반복 가능한 형태로 바꿔 주어야 한다.
- while, for
- 프로그램에서 가장 중요하다! 왜???
- While statement :
= 조건을 만족할 때까지 반복한다.
- While 조건문 모양 :
while (조건):
<statement1>
<statement2>
<statement3>
# (while) 조건이 만족할 때까지, statement1, 2, 3을 반복한다.
- While 조건문 모양 :
> 구구단으로 연습 : [2단]
# number를 1 올려줘라 : number = number + 1 OR number += 1
# number를 1 내려줘라 : number = number - 1 OR number -= 1

> 커피 자판기 연습 :
# 커피 소진 시 보인 문구 까지: while coffee > 0

- For statement :
= 주어진 어떤 대상을 처음부터 끝까지 반복하는 것을 기본으로 함.
- while문 : 조건이 만족하는 동안 반복을 수행
- for문 : 지정 횟수 동안 반복을 수행
- iteratable object(반복 가능한 객체)를 대상으로 수행됨 → 연속형 데이터 타입 변수들
List, Tuple, String, ... - for 조건문 모양 :
for 변수(A의 원소) in A(리스트, 튜플, 문자열, iterator ...):
<수행할 문장 1>
<수행할 문장 2>
. . .
A(iterator...)의 모든 원소를 (자동으로 끝까지) 반복한다.
# '변수'에 'i'를 자주 사용함!
# A의 원소들을 i라는 변수로 반복하겠다.
> 커피 리스트 출력 연습 :

= 리스트의 원소들(i)이 차례대로 "i 변수에 대입된 후 print(i) 문장을 수행"하기 때문에
한 줄씩 나타남.
> for문의 단짝 : range( ) 함수
= 숫자 범위 내의 값들을 자동으로 생성해 주는 함수
e.g. range(1, 5)는 1, 2, 3, 4까지 차례대로 생성해줌. (마지막 숫자는 제외)
(1 <= x < 5)

> 살 수 있는 커피 종류 연습 :
ㄴ 5000원이 있을 때 :

- 내 나름 해석.. :
# for i in range(len(coffees))
ㄴ len(coffees)는 '아메리카노', '카페라떼', ... = 6
ㄴ i는 지정된 변수의 하나하나 차례대로 대입해서 (반복) 실행
# if prices[ i ] <= 5000
ㄴ prices의 원소들을 하나하나 차례대로 대입해서 (반복) 실행했을 때 5000보다 작으면
# print(coffees[ i ])
ㄴ coffees 변수의 원소 이름들을 써라
ㄴ 할인 행사를 해서 커피값이 500원이 싸졌을 때 (3 가지 방법이 있음) :
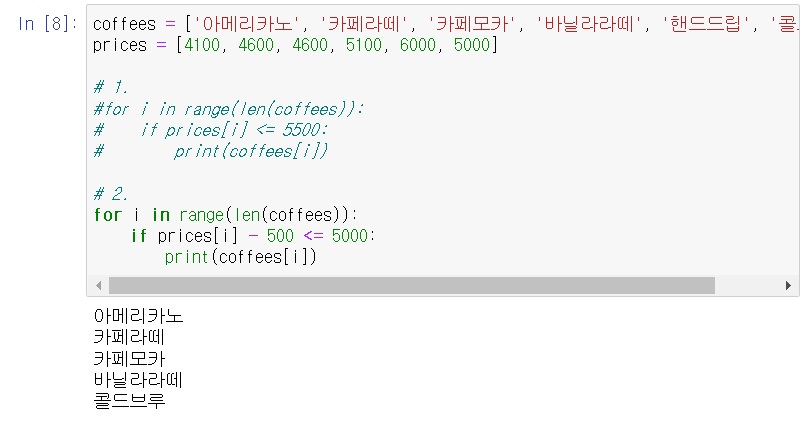
#1 비교하는 값을 5500원으로 올려버리기
#2 prices의 원소들을 500원 깎아버리기

#3 prices의 원소들=가격을 아예 바꿔버리기
> 반복문을 제어하는 break, continue :
1) break statement : 반복문을 수행하다가 더 이상 반복이 필요 없는 경우 🔻
2) continue statement : 반복문을 수행하다가 특정 조건에만 건너뛰고 싶은 경우 🔻
1) 커피가 다 떨어질 때까지 자판기 프로그램을 반복 실행한 뒤, 돈을 입력받아서 커피를 주는 프로그램 :

# while True
= infinite loop 무한루프
# 여기 프로그래밍은 잔액이 부족하면 "반환처리"
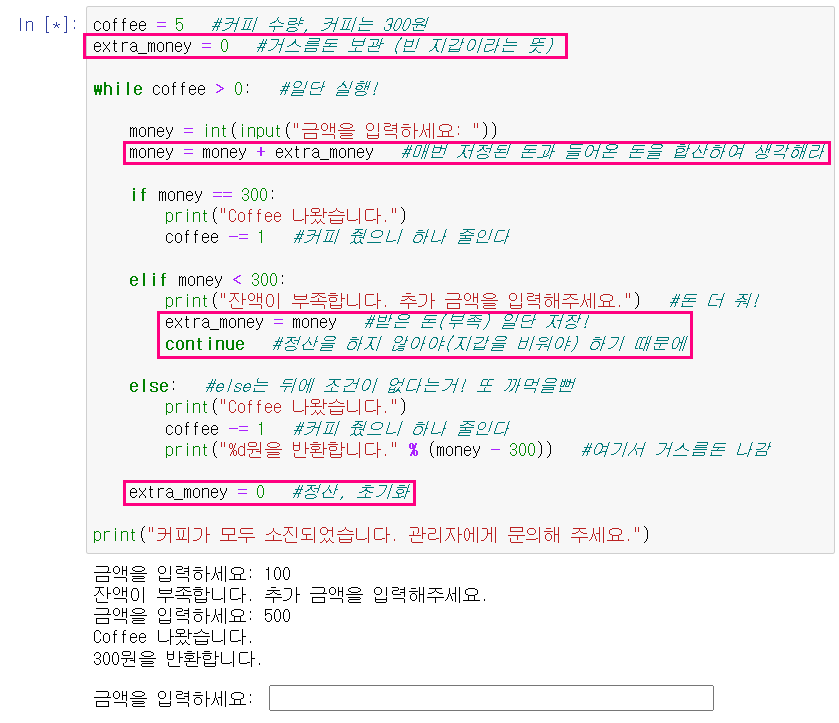
2) 돈이 모자랄 때, 추가로 돈을 입력받아서(300원을 넘는 경우) 커피를 뽑아주는 프로그램 :
# 잔액이 부족하면 "추가 금액 요구" 후, 커피 금액 이상 시 커피 드림
# 부족하게 넣었다 = 넣은 금액 일단 저장(지갑) - 추가금액 입력 - 전에 넣었던 금액과 합산해서 처리!
> nested for문 : 구구단 2~9단
ㄴ for문 안에 for문
ㄴ 여러 번을 여러 번 실행

3. Function
# 함수를 쓰게 되는 케이스가 많다.
# 프로그램을 고급지고 쓰기 편하게 만들 수 있게 된다.
- Function -- Definition :
- Input → (Function) → Output에서 :
input, output = input arameter, output parameter라 부름
output parameter = return을 통해서 함수를 나감 - 하나의 함수 = 하나의 '기능'
- 함수 = 특정 기능을 구현한 '코드 묶음'
- 함수를 쓰는 이유 = '재사용성'
ㄴ 한 번 만들면 필요할 때 가져다 사용 가능.
ㄴ 똑같은 구조의 코드가 반복되는 것을 피하기 위해! - 함수 모양 :
def 함수 이름(param1, param2, ...):
<statement1>
<statement2>
return
- Input → (Function) → Output에서 :
> 간단한 definition 연습 :

# def를 먼저 함으로써 뒤에 함수의 정의를 내려준다.
# add(a, b) 함수 = 입력받은 a, b를 더한 값을 돌려주는 함수
# (a, b)가 연필[parameter들] / def ~ return c가 연필깎이라고 생각하기.
ㄴ 즉, return을 통해 연필을 다시 돌려준다.

# def로 빼기, 곱하기, 나누기의 정의를 먼저 내려준다.
# 곱하기, 나누기처럼 c = ~~ 안 쓰고 바로 return에서 계산 가능 (간단해서?)
ㄴ 0을 나누면 원래 [zero division] 에러가 뜨는데 > 이게 싫고, 다르게 표현하고 싶다면 :

- Function Implementation(응용) :
> parameter & return의 존재 케이스들 :
1) parameter O / return O
def add(a, b):
return a + b
2) parameter X / return O
def get_data(): # 해야될 일이 지정되어 있을 때 사용 가능!
data = pd.read_csv("test.csv") # 정해진 csv파일을 불러오기
return data
3) parameter O / return X
def print_name(name):
print(name)
def save_data(path, data):
data.to_csv(path)
4) parameter X / return X
def say_hi():
print("H!")
def save_txt():
with open("test.txt", "w") as f:
f.write(txt) # 저장 누르면 바로 실행됨ㄴ 만약 함수의 입력 parameter의 개수를 모른다면? :
# *(asterisk)를 앞에 붙여 여러 개의 parameter를 받아서 tuple로 변환하여 준다.
# args = arguments = 변수 이름 → 아무거나 써도 됨


# 튜플로 변했다 = sequence data type이 됐다
= for문을 사용할 수 있다(여기 안에 있는 애들로 무언가 해야지!)
ㄴ 만약 parameter의 개수가 너무 많아서 몇 개만 parameter로 넣고 싶다면? :
# default parameter를 지정한 후, 필요한 parameter만 입력받는다
이렇게 정의된 함수의 parameter = keyword parameter

ㄴ 그래서, 언제 'A'를 함수로 구현해야겠다고 판단할 수 있을까? :
= 똑같은 코드가 2번 이상 반복될 때
= 함수를 짜다 보니 '아, 이거 자주 쓰겠다' 싶을 때가 있을 수도
ㄴ 만약 함수의 parameter 변수 이름 & 함수를 호출하는 argument의 이름이 같은 경우에는? :
# local variable(지역 변수) : 함수 내부에서 사용되는 parameter들은 외부에 영향을 주지 X
ㄴ 즉, 내부에서 생성되고 내부에서 사용되고 내부에서 사라진다
e.g. 오븐을 샀다 = 오븐 내부에서 어떻게 돌아가든, 외부에서는 결과만 신경 쓰는 것
# 변수의 range(효력 범위) : 이 변수를 확인할 수 있는
e.g. 오븐 안에 어떻게 음식이 구워지는지 볼 수 있는 것
# 변수의 lifetime(수명) : 그 변수가 언제 생성돼서 언제 사라지느냐


# 같은 이름을 써도 내부(local), 외부(global) 끼리는 영향을 안 미치기 할 수 있다. (return을 안 써서)
- Lambda Function :
= Lambda Expression
= inline function
# def 명령어 없이 간단하게 정의해서 사용 가능- Lambda 함수 모양 :
f = lambda a, b: a+b # return에 대한 표시
f(3, 5) # add함수처럼 사용 가능
a, b = input parameter
return에 대한 표시 = output parameter
- Lambda 함수 모양 :

ㄴ 리스트의 원소들을 '원소들의 길이'에 따라 정렬하고 싶다면? :
# sort( ) 함수를 쓰면 = alphabetical order로 된다

# lambda 함수를 쓰면

# sort( ) 안에 기준을 정해줄 수 있다
ㄴ 'key'라고 하는 keyword parameter를 넣을 수 있음
# 's의 길이의 원소'를 쓰기엔 너무 복잡하기 때문에
ㄴ key='함수'를 적용한 key값을 만들면, sort( ) 함수에서 적용이 된다.
# 그래서 lambda s : len(s)라는 함수로 key값을 만들어 주면
= "parameter로 's'를 받고 : 's'의 길이를 return 해준다"는 의미가 됨.
ㄴ 즉, "sort(되는 원소들)을 'parameter'로 넣고, 해서 나오는 'output 결과'로 세팅을 하겠다!"는 뜻
- 파이썬에 '이미' 정의되어 있는 함수들 사용해보기 :
ㄴ 내장 / 외장 함수- 파이썬 내에 파이썬을 만든 사람이 제공하는 함수들이 있음
- 불러와서 써야 함
- (누군가가 만들어 놓은) 함수들의 묶음 = '라이브러리' -- 체계적으로 만들어져 있음
ㄴ 수학 계산 연습 -- 절댓값, 올림, 내림 / sine, cosine

# import math = 수학에 관한 라이브러리를 불러오는 기능
ㄴ 복권 숫자 출력해보기 (random) :

# import random = 아무거나 뽑는 기능
# random.sample(range(범위, 범위), 몇 개)
ㄴ 다양한 사전들 사용하기 :

# defaultdict : 초기화가 되어 있는 사전 -- 다 0으로 초기화되고 + key값을 넣어주면 그렇게 업데이트됨
# OrderedDict : 입력/저장한 순서대로 기억하는 사전


4. 데이터 입출력 I/O (Input/Output) :
- I/O란? :
- I/O의 기준 = program 입장에서 들어오고 나가는 모든 데이터
- I/O 처리 = 메인 메모리 입장에서 생각하는 들어오고 나가는 모든 데이터 (단, CPU와의 소통 제외)
- stdin = 사용자로부터 키보드로 입력받는 것 (standard input)
- stdout = 사용자에게 다시 모니터로 출력되는 것 (standard output)
- program은 메인 메모리 상에 존재하기 때문에 storage로부터 파일을 불러오는 것도 = input
program의 결과를 storage에 저장하는 것도 = output
ㄴ 이러한 작업을 file I/O로 통칭함- storage와 program 사이의 I/O를 file I/O라고 함
- stdin/out 사용하기 :
> 방법 :
# input( ) 함수를 통해 stdin을 사용자로부터 입력받을 수 있다.
# print( ) 함수를 통해 stdout을 사용자에게 출력할 수 있다.


# 파이썬은 input( ) 함수로 받은 모든 입력을 'string'으로 자동 전환한다!
ㄴ 그래서 input 앞에 int를 붙여줌으로써 '명시적 타입 변환'을 한다 = type casting
ㄴ 만약 stdin으로 여러 개의 숫자가 들어오는 경우, 입력의 format을 알고 있다고 가정했을 때, 이를 효과적으로 처리할 수 있을까? :

# 2개 정도의 숫자라면 그렇게 귀찮지만은 않음... 하지만 10개, 30개.. 라면?
ㄴ 즉, 몇 개가 들어올지 모를 때 기존에 방식 :
1) 일단 숫자들을 다 받는다
2) sequence data type으로 바꾼다
3) for문을 통해 처리한다
말고 → list comprehension라는 고급 기술 사용! (간결하고 효율적임)
= list를 생성하는 어떤 expression (expression에 규칙이 있음)
1. 원소가 될 원소의 expression (원소를 어떻게 나타낼 것이냐)
2. 반복문
3. (선택) 조건


→ 한 줄 해석 = list인데 - 원소가 input 함수로부터 입력받은 string을 - ', ' 기준으로 split 해서 - 하나하나의 원소를 숫자로 바꾼 원소를 - 가지고 있는 list.


- file I/O 사용하기 :
> 방법 :
# open( ) 함수를 이용하여 파일을 쉽게 열 수 있다.
# close( ) 함수를 통해 닫아줘야 한다. (close 안 하면 jupyter가 계속 일해서 시스템 낭비임)
# open( ) 함수는 기본적으로 txt 파일을 연다. (다른 타입 파일 열려면 다른 라이브러리 필요)
e.g. csv, excel 파일 열려면 pandas, csv, openpyxl 라이브러리 사용 가능
# txt 파일 열려면 read( ), readline( ), readlines( ), + for문 이용 가능
f.read( ) : txt 파일에 있는 모든 글자를 가져와서 하나의 string으로 저장해라
f.readline( ) : txt 파일에 있는 첫번째 줄만 가져와라
f.readlines( ) : txt파일에
# '\' = 애플에 '역/'
'\n' = enter
ㄴ f.read( ) 함수 :

TMI :
사실 텍스트 파일 하나 열겠다고 3일 정도 걸렸던 것 같아요..
보조강사님께 한 번 여쭤 봤으나, 그래도 열리지가 않았어요.
아무리 구글링 해보고 다양한 방법으로 해도 Pandas 외에는 왜 열리지가 않는 건지 ㅠㅠ
결국 고민 끝에 보조강사님께 다시 한번 여쭤보니 mode뒤에 encoding='UTF-8'을 추가하라고 하셨습니다!
드디어.. 성-공 (감격🥲)
ㄴ f.readline( ) 함수 :

ㄴ f.readlines( ) 함수 :
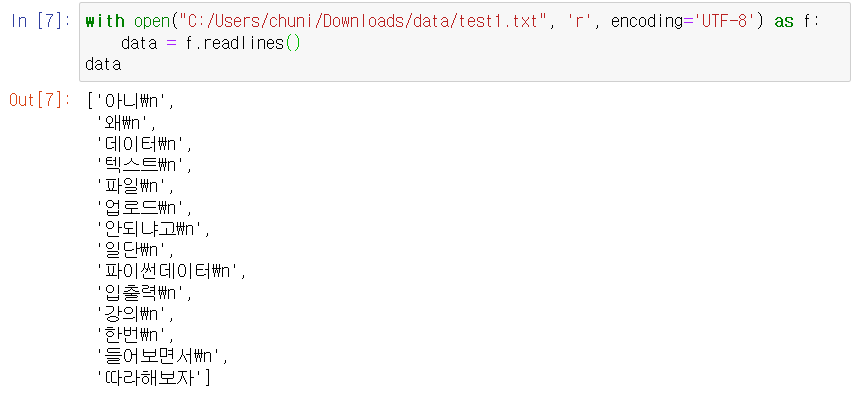
ㄴ for문 :
= 자동으로 한 줄씩 내려간다.

I/O Implementation :
ㄴ 3 글자 이하를 다 지우고 다시 저장하고 싶다면? :
1) 3 글자 이하 지우기

2) 다시 저장하기


# 저장할 땐 read mode가 아니라 write mode인 'w'를 사용한다

ㄴ pickle 라이브러리를 통해 파이썬 object 자체를 저장하는 방법 :
output은 위와 같다.

# wb = write as binary
rb = read as binary
# pk 파일은 0101로 된 binary파일이기 때문
ㄴ 파이썬 라이브러리를 통해서만 읽어올 수 있다.
5. Numpy
- numpy란? :
= Numerical Python의 약자
# Numerical Computing : 컴퓨터가 실수 값을 효과적으로 계산할 수 있도록 하는 연구 분야
# Vector Arithmetic : 벡터(숫자의 모음) 연산 → 데이터가 벡터로 표현되기 때문- 다양한 머신러닝 라이브러리들에 의존성을 가지고 있다 (성능 : python list(tuple) <<< numpy array)
- numpy array (python list와 비슷한 개념)
# 파이썬 리스트처럼 여러 데이터를 한 번에 다룰 수 있으나, 모든 데이터가 동일한 data type을 가져야함!
# numpy array 사용하는 가장 큰 이유는 vector처럼 사용할 수 있기 때문 - C언어, JAVA의 array와 비슷, 동적 할당(dynamic type binding)을 지원하는 파이썬의 리스트와는 구조가 다름
- numpy array 특징 :
> 모든 원소의 자료형이 동일해야 함
> 선언할 때 지정한 크기 변경 불가능 / 원소 update는 가능
# append함수가 있지만 의미가 다름 → 크기를 변경하면 '복사'함
> C, C++로 구현되어 있음.
ㄴ high performance를 내기 위함
ㄴ python이 numerical computing에 취약하다는 단점 보완 가능
(파이썬의 부족함을 다른 언어로 구현한 것을 가져와 도움을 받음)

> numpy array가 python list보다 빠른 이유 :
# 데이터 타입이 똑같기 때문 # universal function을 제공하기 때문에 같은 연산 반복에 대해 훨씬 빠름
# 데이터의 크기가 클수록 차이가 더 큼
- numpy : 심플! 데이터 확인 → 얼마나 큰지 확인 등 한번에 끝.
- python : 어느 방에 뭐가 있는지 찾아가는 구조(찾기엔 쉬우나) → 대용량일 땐 느려질 수밖에
- numpy array 만들기 :
1) numpy 라이브러리 불러오기
# 줄여서 np

2) 파이썬 리스트 선언하기

3) 파이썬 2차원 리스트(행렬) 선언하기

4) 파이썬 리스트를 numpy array로 변환하기
# numpy.ndarray = ndarry(n-dimensional array) : numpy를 사용할 때 벡터(다차원)로 지원할 수 있다는 뜻
# numpy array 만드는 방식 대부분 : 파이썬 리스트 → np.array로 변환
# np.array(1, 2, 3, 4, 5) X
np.array(( 1, 2, 3, 4, 5)) O
np.array([ 1, 2, 3, 4, 5]) O
# np.array.shape = np.array의 크기를 알려줌
행렬 크기 표현 = (5, ) = 5 x 1 (1 생략함)
# arr = array 줄인 표현

5) 2차원 리스트를 np.array로 만들기

6) array 연산자
- print("arr2의 ndim : ", arr2.ndim) # arr2의 차원
- print("arr2의 shape : ", arr2.shape) # arr2의 행과 열의 크기
- print("arr2의 size : ", arr2.size) # arr2의 행 x 열 (곱하기)
- print("arr2의 dtype : ", arr2.dtype) # arr2의 원소의 타입 (int32 : integer + 32 bits)
- print("arr2의 itemsize : ", arr2.itemsize) # arr2의 원소의 사이즈(bytes) (32 bits = 4B)
- print("arr2의 nbytes : ", arr2.nbytes) # itemsize x size (= numpy array가 차지하는 메모리 공간)

- numpy array 사용하기 :
ㄴArray Initialization :
# numpy array를 초기값과 함께 생성하는 방법 :
ㄴ 한번 만들면 변경 불가이기 때문에 0이나 1로 초기화되어있는 array를 먼저 만들려는 것
1) np.zeros( ) = 원소가 0인 array를 생성
2) np.ones( ) = 원소가 1인 array를 생성
3) np.arange( ) = 특정 범위의 원소를 가짐

ㄴ Array Operation → Universal Function :
> numpy array == vector처럼 사용할 수 있어서 편리함
> scipy, matplotlib, 등 대부분의 수치를 다루는 데이터 분석 라이브러리들이 vector를 사용함
vector → numpy array로 표현이 가능.
> numpy array vector를 연산하려면 원소의 개수가 같아야 함 → 'broadcast'

# dot product = v1 @ v2
ㄴ Broadcast :
= 서로 크기가 다른 numpy array를 연산할 때, 자동으로 연산을 전파해주는 기능
ㄴ 특히, 행렬 곱하기할 때 편리함
# (2, 3) = 2 by 3 = 2개짜리가 3줄 있다
# (3, ) = 3 by 1 = 3개짜리가 1줄 있다

# 작은 행렬이 더 큰 행렬을 각각 +-x/ 해줌


ㄴ Universal Functions (UFunc):
= 하나의 함수를 모든 원소에 자동으로 적용해주는 기능
그래서, 모든 원소에 대해 같은 작업을 처리할 때 엄청나게 빠른 속도를 낼 수 있음
# 정수(int)를 실수(float)로 바꾸고 싶을 때 :
= arr1 / 1

# 모든 원소를 역수를 취하려면 :
= 1 / arr1

# 모든 원소에 2를 더하려면 :
= arr1 + 2

ㄴ Indexing (=python list, but more POWERFUL) :
- 리스트에서는 안 되는 어마어마한 기능이 있음
- pandas에서 유용함 (그전에 numpy에서 익히기)
- 인덱싱의 이해를 잘하면 -- excel 보다 조금 더 직관적이고 편하고 빠르다고 느껴질 수 있음
# 일단 기본은 리스트와 같다 :

# 2차원 numpy array로 세팅하면 :
ㄴ 1번째 row : 0, 2번째 row : 1 | [5,6,7,8]에서 3번째 원소 : 2
arr2[1][2] == 2번째 row의 3번째 원소
= arr2[1, 2]

ㄴ 전체 rows/columns == :
arr2[ :, 2] == 전체 rows에서 3번째 원소들만 인덱싱
arr2[1, : ] == 전체 columns에서 2번째 행(row)만 인덱싱

ㄴ Masking :
= 0 & 1인 비트 연산으로 일부만 필터링

# mask 만들기 → True / False로 나타남 :

# 위에서 생성한 data에 mask 적용시키기 :

ㄴ ' : ' = all columns
# mask를 0으로 바꿔보기 (바로 바꾸는 방법) :

# fancy indexing을 이용해서 masking :


# 2차원 data에서 첫 번째 column에 0보다 작은 원소들을 0으로 치환 :
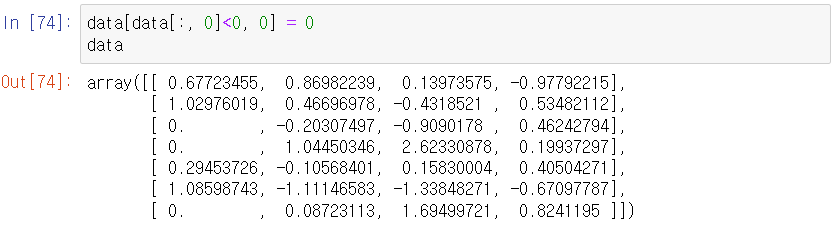
# 위 상황을 전체 데이터에 적용 :

ㄴ numpy Methods :
굉장히 많은 함수들 중 많이 사용하는 함수들! (굳이 모두 외울 필요 x, 필요할 때마다 구글링 하면 됨)
# 표준 정규분포(평균 0, 범위-1~1)에서 random sampling을 한 원소를 가지는 5x3 행렬 :
ㄴ 이건 어떻게 알 수 있나?
= randn click → [shift + tab]


# mat1의 절댓값 :

# mat1의 제곱근(square root) :
nan = imaginary number


# mat1의 제곱 값(square) / 지수값(exp) :

# log들 (상용로그, 이진 로그) :
- 로그는 음수(-)가 없기 때문에 nan(imaginary number)로 뜬다

# 부호 찾기(sign) / 올림(ceil) / 내림(floor) :

# 존재하지 않는 값이 있는지 없는지 :

# sin, cos, tan, hyperbolic tangent :

# mat2를 만들어서 -- 두 개의 matrix 중에 큰 것만 쓰기 :

ㄴ Reshaping array :
# 첫 번째처럼 쓰면 수가 커질수록 힘듦.. 핑크박스 = np.arange(a, b).reshape(c, d) 함수 사용 :

# transpose :


ㄴ Concatenation of arrays (연결, 이음) :
np.concatenation(( ))


ㄴ Aggregation functions (집계 함수) :
# mat1의 total sum, column/row sum, mean :
np.sum( )
np.mean( )

# mat3

# mat3의 standard deviation, column/row's min & max :
np.std( )
np.min( )
np.max( )

# mat3의 최솟값이 있는 'index'를 알고 싶을 때, cumulative(누적) sum/product :
np.argmin( )
np.argmax( )
np.cumsum( )
np.cumprod( )

# 정렬 :
np.sort( )

np.argsort( )
# argument sorting에서 정렬된 값의 원래 위치 -- smallest value(0) ~ (2)biggest value [row]
= np.argsort(mat3, axis=1)

# 정렬된 다음의 index를 원래 원소의 위치에 표시 -- (0) ~ (4) [column]
= np.argsort(mat3, axis=0)

2주 차 후기.
스크롤이 끝이 없네...
파이썬은 하다가 막히면 진도가 1시간+는 정체되는 것 같다ㅋㅋ
그래도 이렇게 정리를 해놔야 나중에 기억이 안 날 때 ctrl+F로 찾아보기 편할 것 같아서
이 악물고 하는 중이닷!😬
아직도 이해가 잘 안 되는 부분들이 조금 있고
하루 정도 강의 링크에 오류가 생겼어서 하루를 날리긴 했지만
3주 차도 파.. 파이팅! ⭐
'공부zip. > 데이터사이언스' 카테고리의 다른 글
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 3.1 (0) | 2022.03.17 |
|---|---|
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 2.1 (0) | 2022.02.25 |
| [패스트캠퍼스 국비지원교육 개발노트] 데이터분석 인강_week 1 (0) | 2022.02.25 |




댓글